开源的大模型训练语料
本文汇总了当前包括中英文开源的大规模预训练数据集。目前的核心观点是: 大规模高质量的网络数据 is All you Need,无需手工精心调配各种数据源,例如百科,书籍,代码等。
| 数据集 | 语言 | 发布机构 | 发布时间 | 数据规模 | 数据来源 | 训练的模型 |
|---|---|---|---|---|---|---|
| Pile[1] | 英文 | Pile | 2020 | 800GB | 22个不同的数据集,包括百科/代码等 | PaLM, Chinchilla |
| RefinedWeb[2] | 英文 | EleutherAI | 2023 | 600B token | 网络数据CC | Falcon |
| ChineseWebText[3] | 中文 | 中科院自动化所 | 2023 | 1.42TB | 网络数据CC |
Pile
Pile是EleutherAI发布的一个英文的预训练语料。涵盖了22个不同的数据来源,包括作者新构建的ArXiv, GitHub等,还包括已有的Books3,English Wikipedia等数据集。
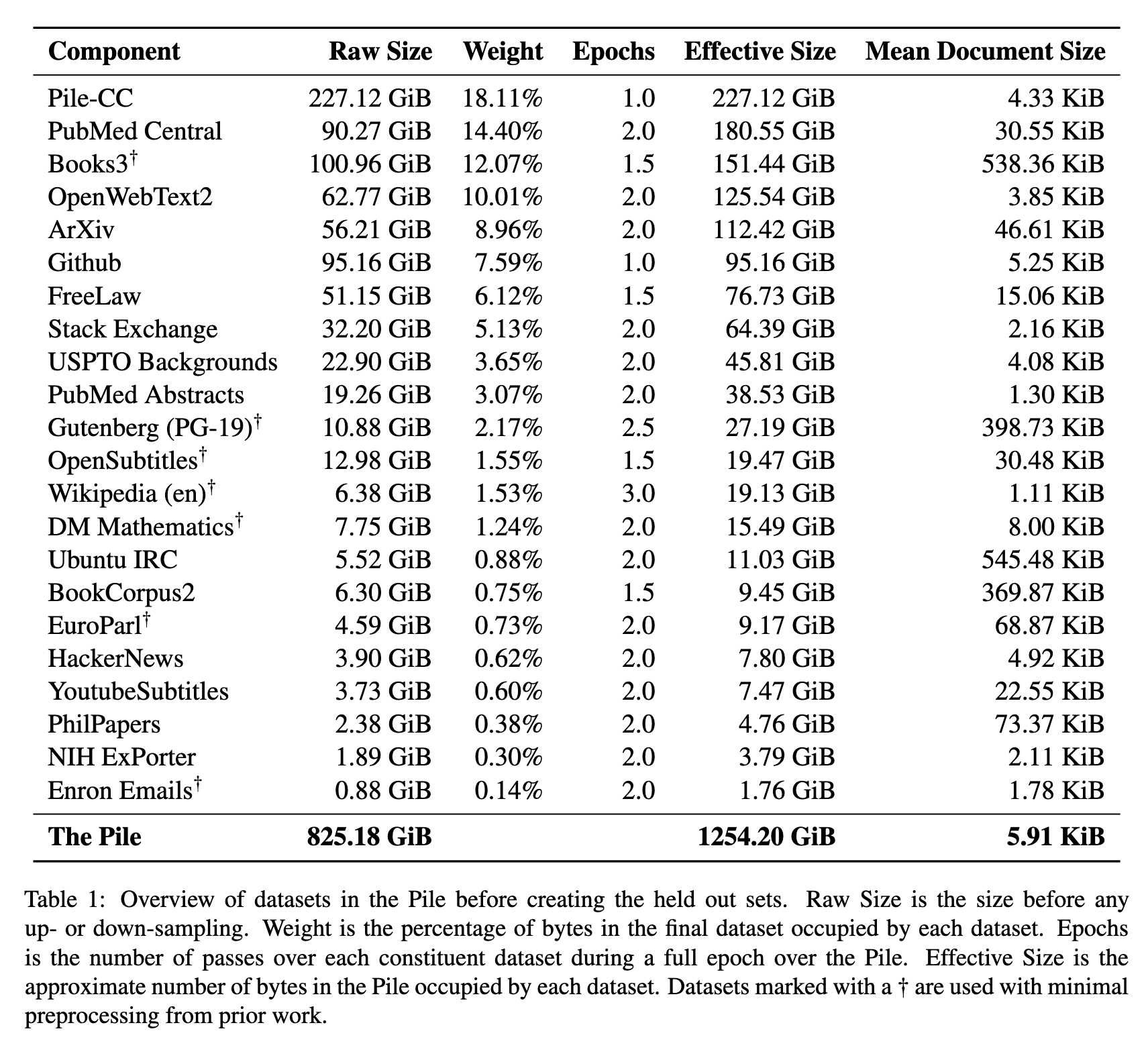
实验表明:
- Pile是一个好的训练语料,因为融合了多种数据来源,相比当时其他训练的数据集(例如C4),基于Pile训练的模型性能更好
- Pile是一个好的评估语料,可以评估模型在不同领域的性能,例如代码,学术等,相比其他评估数据,更加鲁棒,能更全面反映模型的世界知识和推理能力。
RefinedWeb
RefinedWeb是Falcon发布的一个英文的预训练语料,仅包含网络数据,共5T,开源了其中的600B数据。
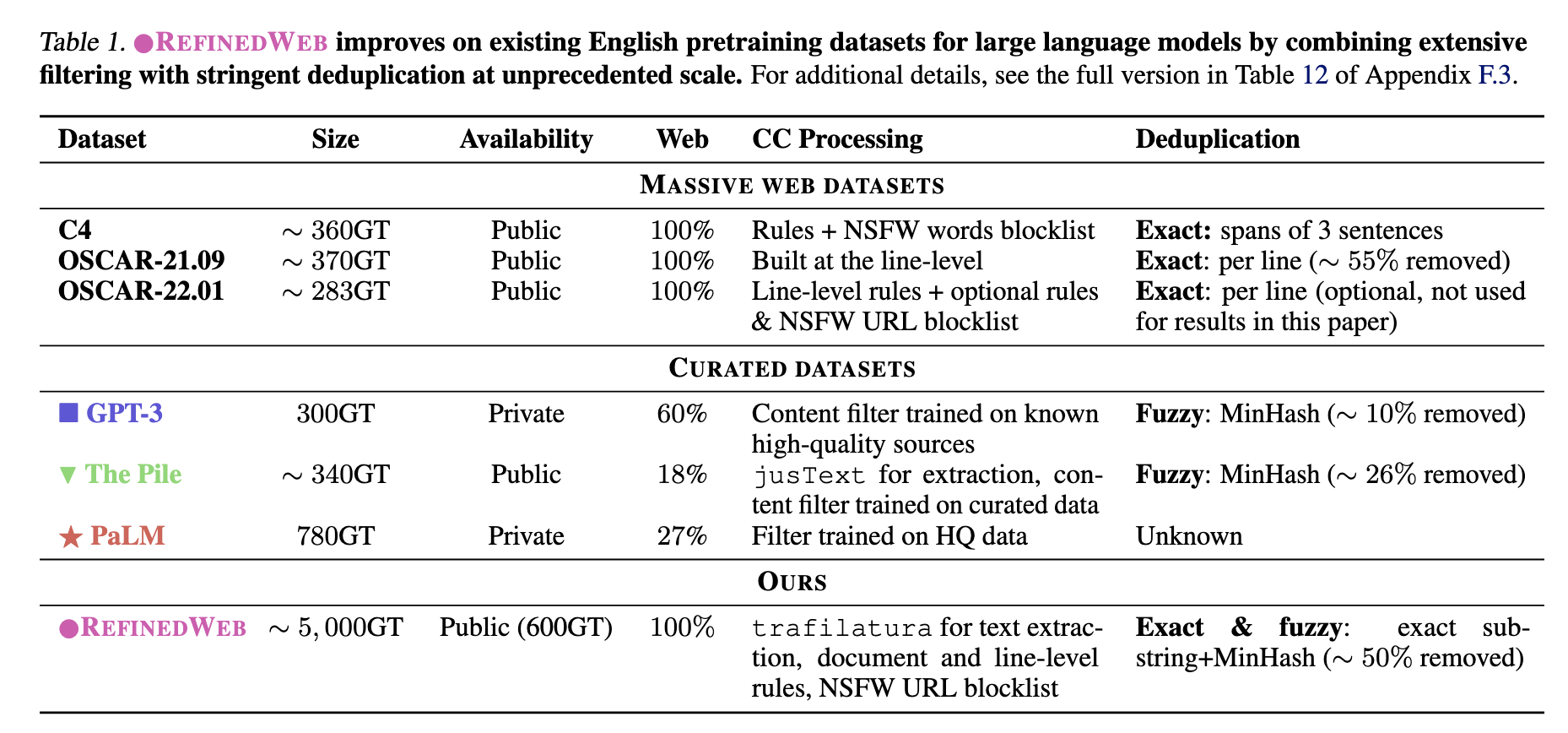
作者的核心观点是,不需要精心手工构造数据源(百科,书籍等),而是直接采用大规模高质量的网络数据即可。实验表明,仅通过高质量的网络数据训练出的模型比传统手工构建的数据集效果更好。
即Pile之所以能比网络数据C4效果好,不是网络数据的问题,而是C4的数据规模太小,清洗规则有偏。同样的网络数据RefinedWeb就比Pile更好。
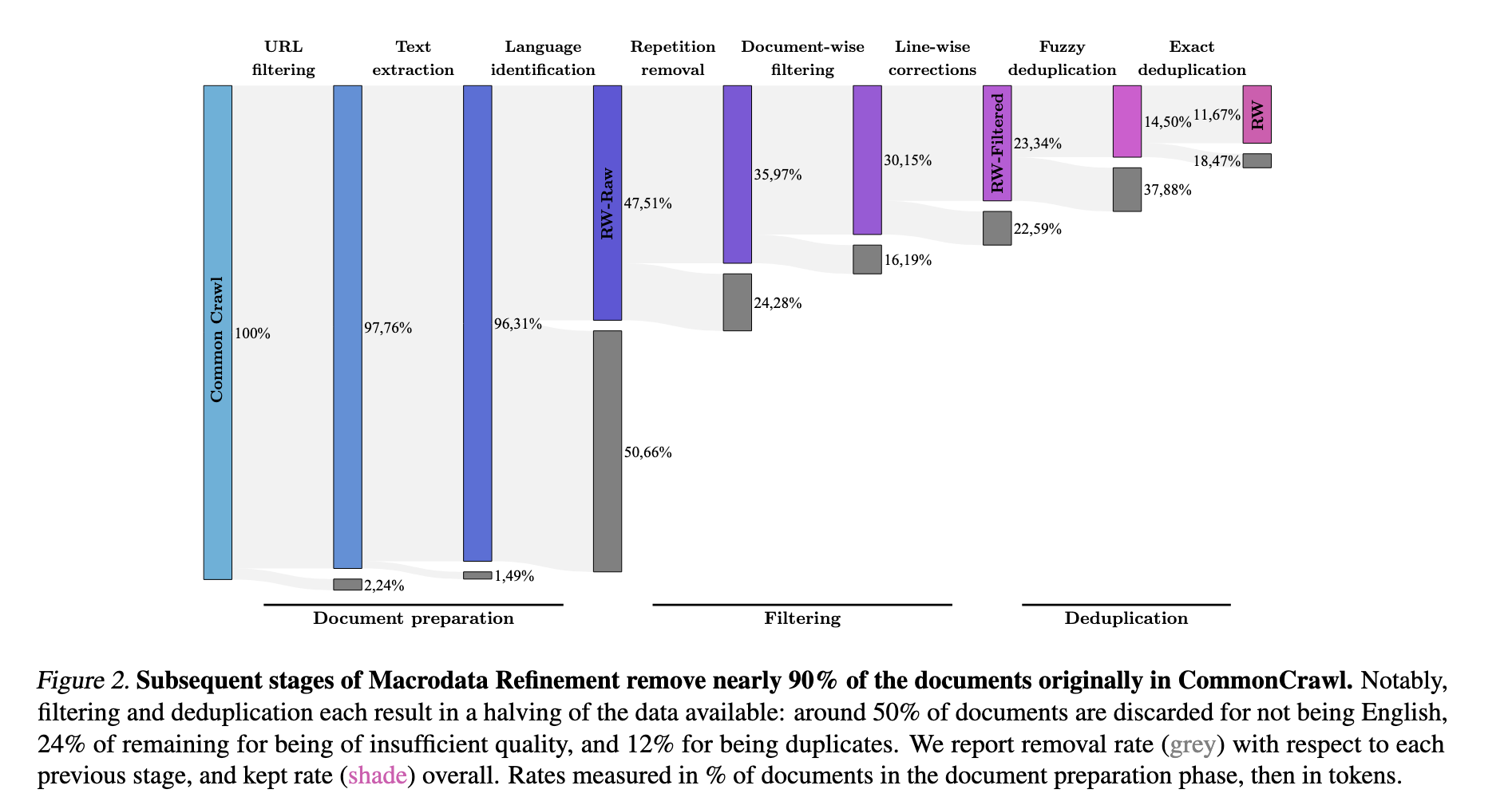
这个工作的核心如何对网络数据进行清洗,进而无偏地提取出高质量的网络数据。作者提出的pipeline包括:
- URL过滤,这里不仅过滤了低质有害的URL,还过滤了传统高质量的URL,包括维基百科,arxiv,Github等。
- 文本内容提取
- 语言识别
- 低质过滤,文档级别+行级别
- 去重,模糊+精准
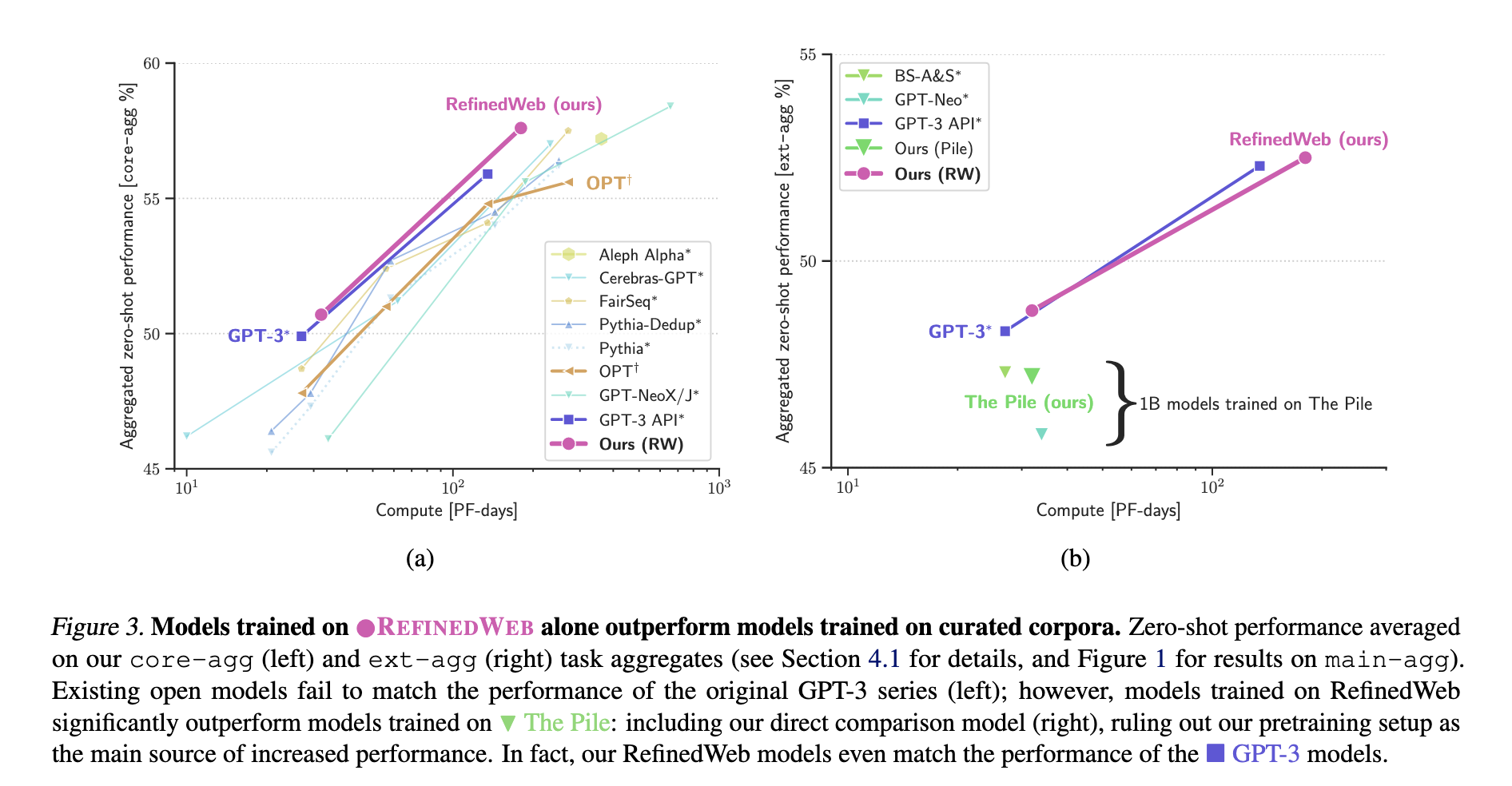
结果显示,仅使用web数据,并且排除了高质量的传统数据源(百科,code等),效果依然比手工精心构建的不同数据源的训练数据要好。
ChineseWebText
ChineseWebText是按照RefinedWeb的思路做的中文版本,由中科院自动化所发布,仅包含网络数据,共1.42TB,并且每条数据都有一个打分,其中高质量数据有600GB。
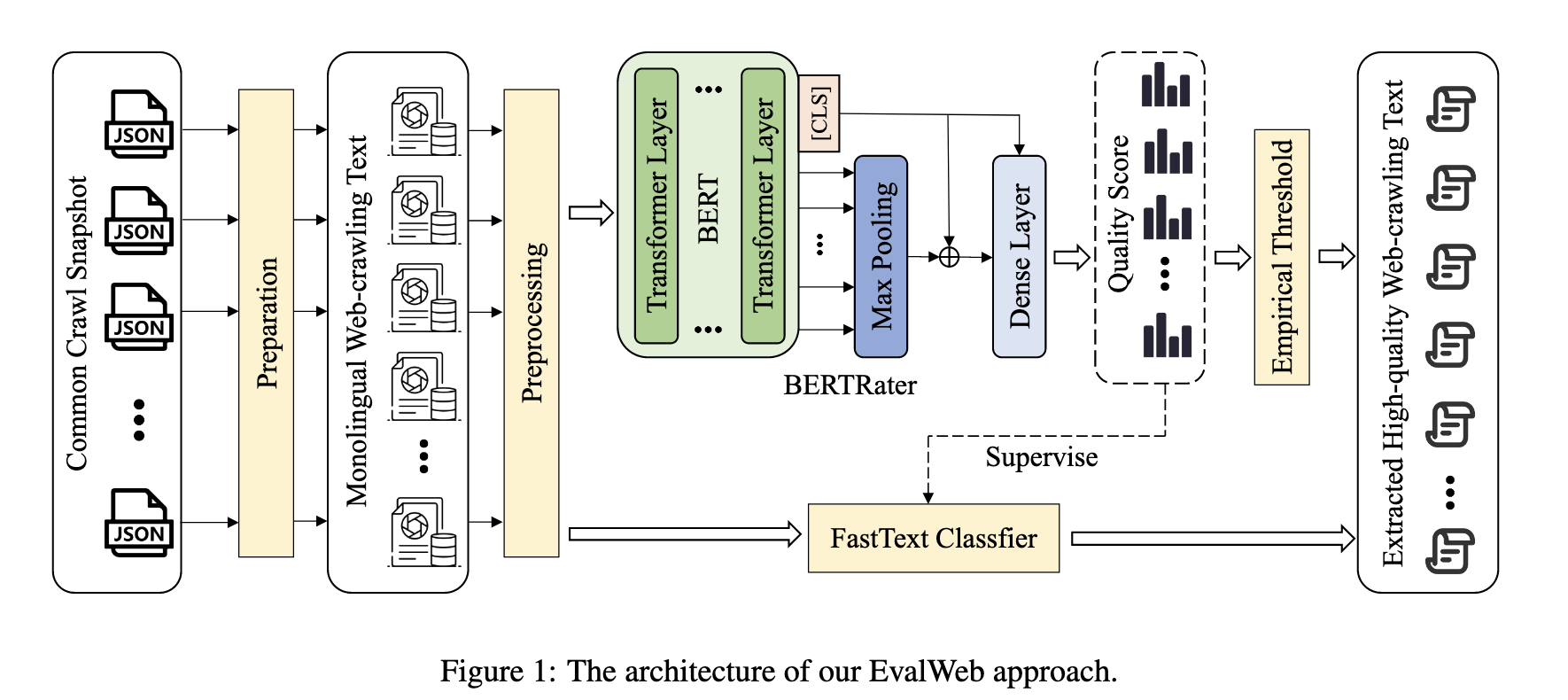
作者提出了EvalWeb的数据处理pipeline,包括下面几个步骤:
- 数据收集:基于CommonCrawl收集最新的9个快照,2021-43->2023-23
- 数据准备:去重复,并过滤出中文内容
- 数据预处理:文本内容提取,短文本过滤,繁体中文过滤,中文占比较低的文本过滤,含敏感词的文本过滤,篇内重复文本过滤
- 质量评估:包括基于BERT和FastText的过滤方法
通过对每条文本基于BERT进行打分,基于阈值为0.4过滤出高质量文本600GB。基于这个阈值过滤的文本,人工评估显示90%均为高质量的文本。
不过相比RefinedWeb,本文没有具体的训练模型进行对比,所以基于该数据集训练的模型实际效果还有待验证。
参考
- [1] The Pile: An 800GB Dataset of Diverse Text for Language Modeling
- [2] The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only
- [3] ChineseWebText: LARGE-SCALE HIGH-QUALITY CHINESE WEBTEXT EXTRACTED WITH EFFECTIVE EVALUATION MODEL
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!