RLHF实践-以baichuan为例
本文分享基于Baichuan的RLHF实践,包括reward模型训练,PPO和DPO的理论以及实际的调参经验。如果你也在做RLHF,欢迎私信一起交流。
RLHF的动机
(1) reward模型很有必要
reward模型评估效果理论上能逼近于人工评估,并显著优于传统的BLUE等指标。所以从这个角度看,即使不做后面RL部分,获得一个靠谱的reward的模型也对业务有很大帮助。基于reward模型,可以评估现有模型,过滤训练数据中的脏数据等等。
(2) 突破标注者的上限
生成任务往往是没有标准答案的,所以模型的上限直接取决于标注者的标注水平。以机器翻译为例,能翻译出“信达雅”标注人员是非常昂贵的,所以给到的SFT数据一般是普通的标注人员标注的。所以如果只做SFT阶段,模型是有天花板的,通过RL可以让模型突破天花板,生成的效果有机会能超过人类标注者。
框架选型
推荐trl,hugginceface出品。如果你习惯hugginceface的trainer,trl上手会非常快,并且同时支持PPO和DPO两种算法,也有丰富的例子和文档。
Reward
模型
Reward模型本质是一个句子级的分类,对于baichuan模型,需要手工添加类BaiChuanForSequenceClassification,可参考LlamaForSequenceClassification。
Reward模型需要基于SFT模型进行初始化。如果是基于lora进行训练,lora的task type需设置为TaskType.SEQ_CLS.
数据
reward部分的难点是如何收集偏好数据,具体需要:
- 高质量: 对于一条偏好样本,例如A > B,不同标注者的观点是一致的,没有很大分歧
- 足够多: 尽可能覆盖各种场景,例如不同的长度,避免在RL阶段出现OOD,然后崩掉
这里可以参考OpenAI的paperLearning to summarize from human feedback,里面有如何标注偏好数据的详细描述。
另外,如果想用GPT4替代人工进行标注,需要仔细优化prompt和二次验证。数据质量 >> 数据数量。
训练
如果SFT模型和偏好数据一切正常,就可以获得如下的预期结果: loss下降,accuracy上升
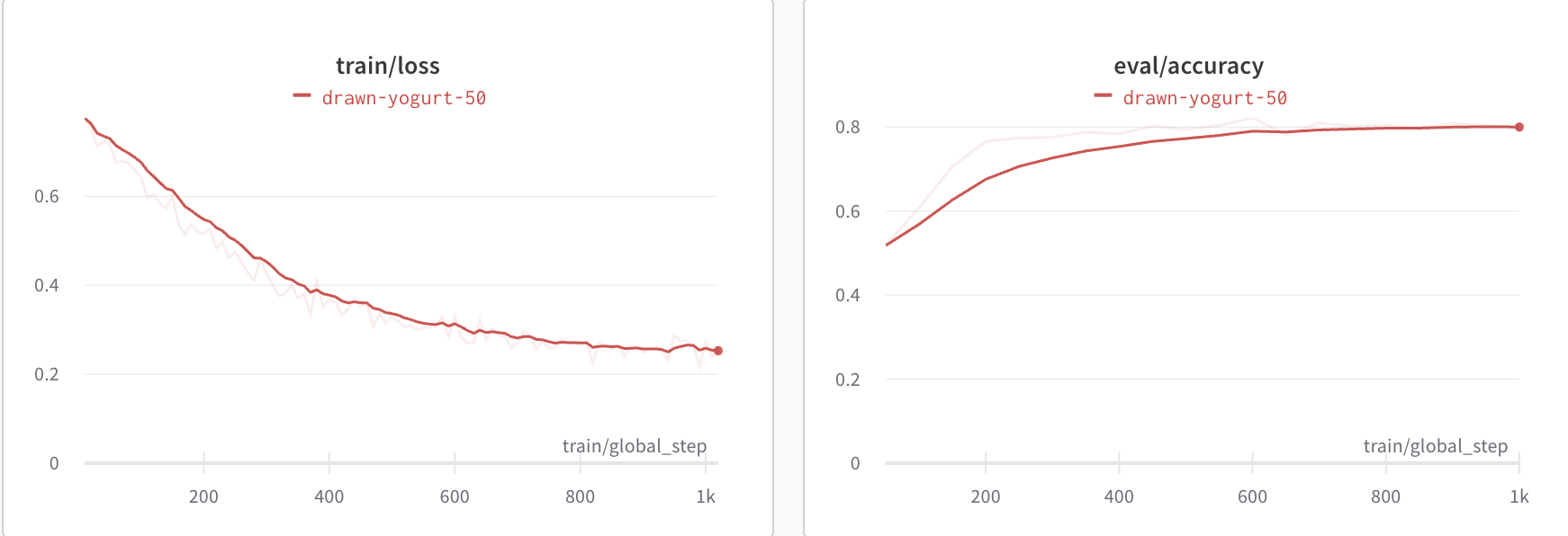
根据baichuan/llama的技术报告,一般reward模型的准确率到80%,就算是一个还不错的reward模型。 如果reward训崩了,大概率是数据的问题,需要严格检查数据质量。
PPO
有了相对不错的reward模型就可以进入到RL部分,PPO是目前最广泛应用的RL算法,也比较复杂。
理论
理论部分,推荐TRiddle大佬写的解析文章:拆解大语言模型RLHF中的PPO
具体而言,PPO包括4个模型: actor(真正优化的,需训练), cirtic(评估的,需训练), reward(上一步获得的reward模型,无需训练), ref(SFT模型,无需评估)
PPO的训练目标如下: 第一项的reward要尽可能大,同时第二项与SFT模型的偏移要尽可能小
对照读trl实现的源码: https://github.com/huggingface/trl/blob/main/trl/trainer/ppo_trainer.py
PPO可以分成三个阶段: 采样,反馈 和 学习
1 | |
实践
PPO的训练是不稳定的,同样的参数和数据,不同随机数跑多次,结果差异也会很大,例如: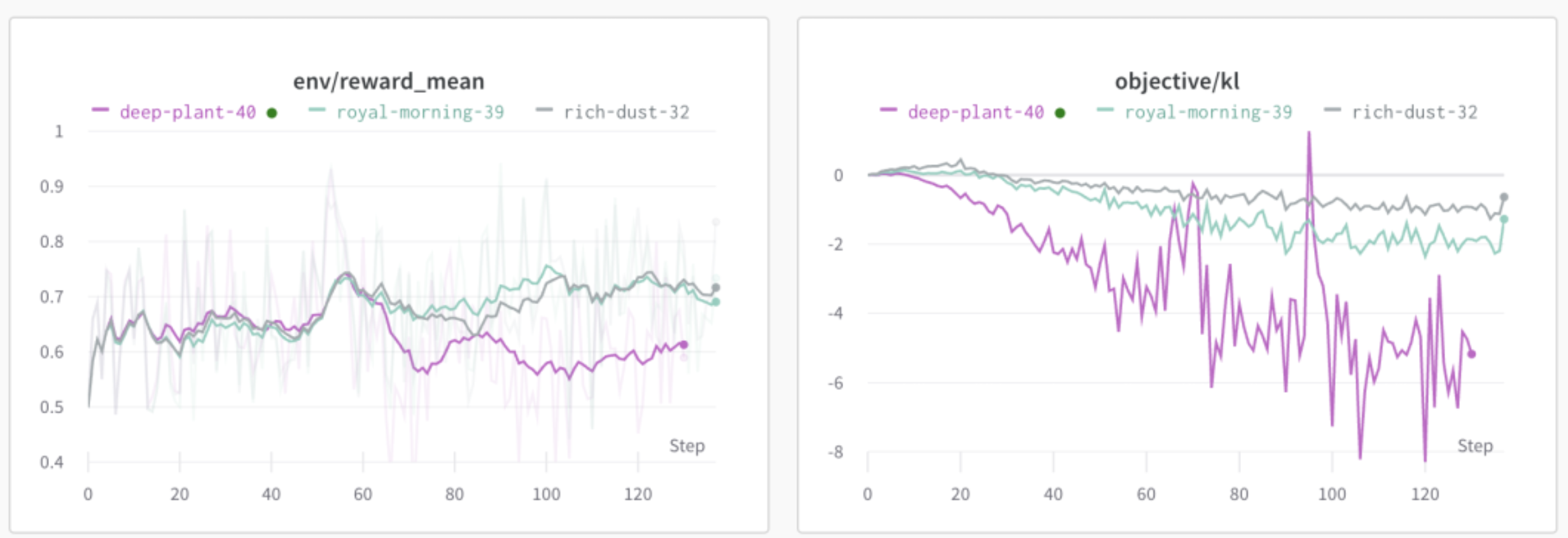
具体可调节的参数非常多,下面是一些可以尝试的项:
1 | |
具体实践上,有一些小tips可供参考:
- 确保reward模型的质量,可以随机测一些corner case。如果reward模型不好,PPO训练失败概率很大
- 关注输出长度,如果出现长度超长/超短,训练大概率会崩溃
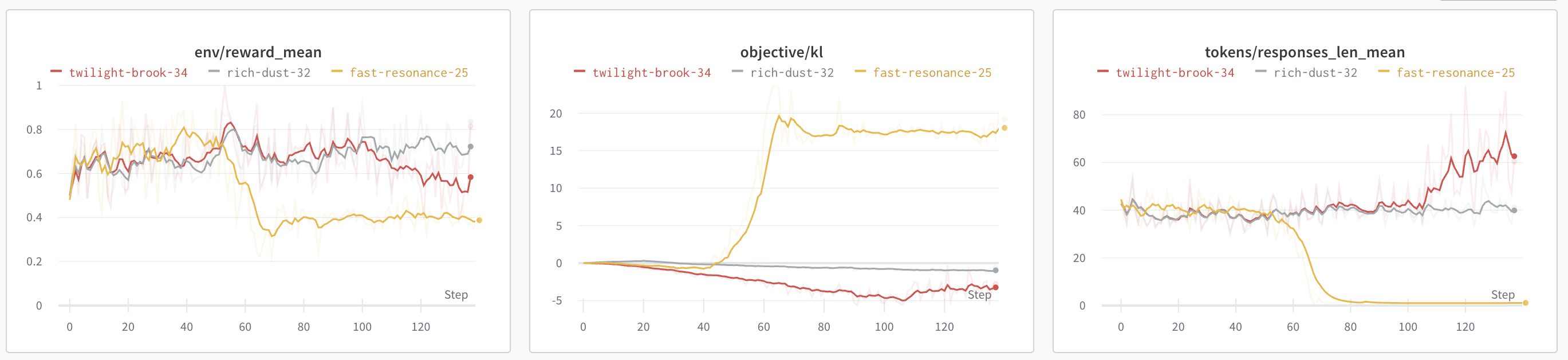
- 固定一些case进行debug,每次PPO迭代后观察这些case是否有改变(变好?变差?崩了?)
- 如果出现KL为负数,类似下面的警告,可能跟generate config有关,也可以调整kl的计算方式。
具体参见: https://huggingface.co/docs/trl/main/en/how_to_train#what-is-the-concern-with-negative-kl-divergence1
UserWarning: KL divergence is starting to become negative: -2.04 - this might be a precursor for failed training. sometimes this happens because the generation kwargs are not correctly set. Please make sure that the generation kwargs are set correctly, or review your training hyperparameters.
如果一切顺利+运气不错,可以观测到相对稳定的reward提升,同时kl也没有很大偏移
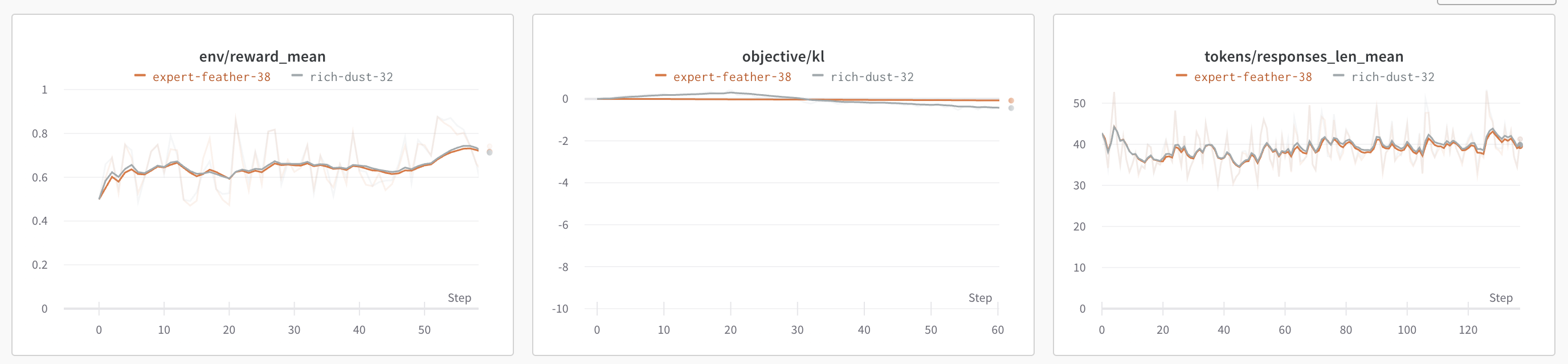
DPO
如果觉得PPO不稳定,太复杂,那可以试试DPO(Direct Preference Optimization),同样有效,但简单很多!
DPO无需reward模型,无需RL,也无需4个模型,就1个模型,直接在偏好数据上进行监督训练。
理论
DPO的paper为: https://arxiv.org/abs/2305.18290
DPO的训练目标如下: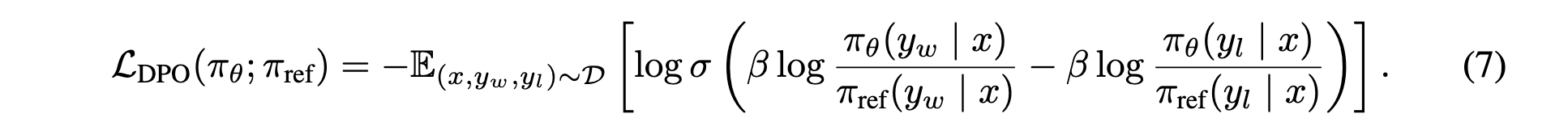
可以认为希望左半部分和右半部分的margin越大越好。左半部分是「优化模型」相比「原始SFT模型」在「偏好数据中good case上」的差值;右半部分是「优化模型」相比「原始SFT模型」在「偏好数据中bad case上」的差值。
所以margin变大有下面几种情况:
(1) 左边变大,右边变小: 「good case」上「优化模型」比「SFT模型」的生成概率变高,同时「bad case」上「优化模型」比「SFT模型」的生成概率变低。说明生成goodcase概率提升,同时生成badcase概率降低,模型整体变好。
(2) 左边变小,右边更小: 「good case」上「优化模型」比「SFT模型」的生成概率变低,同时「bad case」上「优化模型」比「SFT模型」的生成概率变得更低。说明生成badcase概率大幅降低,模型整体变好。
(3) 左边更大,右边变大: 「good case」上「优化模型」比「SFT模型」的生成概率变得更高,同时「bad case」上「优化模型」比「SFT模型」的生成概率变低。说明生成goodcase概率大幅提升,模型整体变好。
实践
基于偏好数据直接对模型进行微调即可,如果偏好数据正常,一般都是能稳定收敛的。可以观测到margin变大,acurracy提升。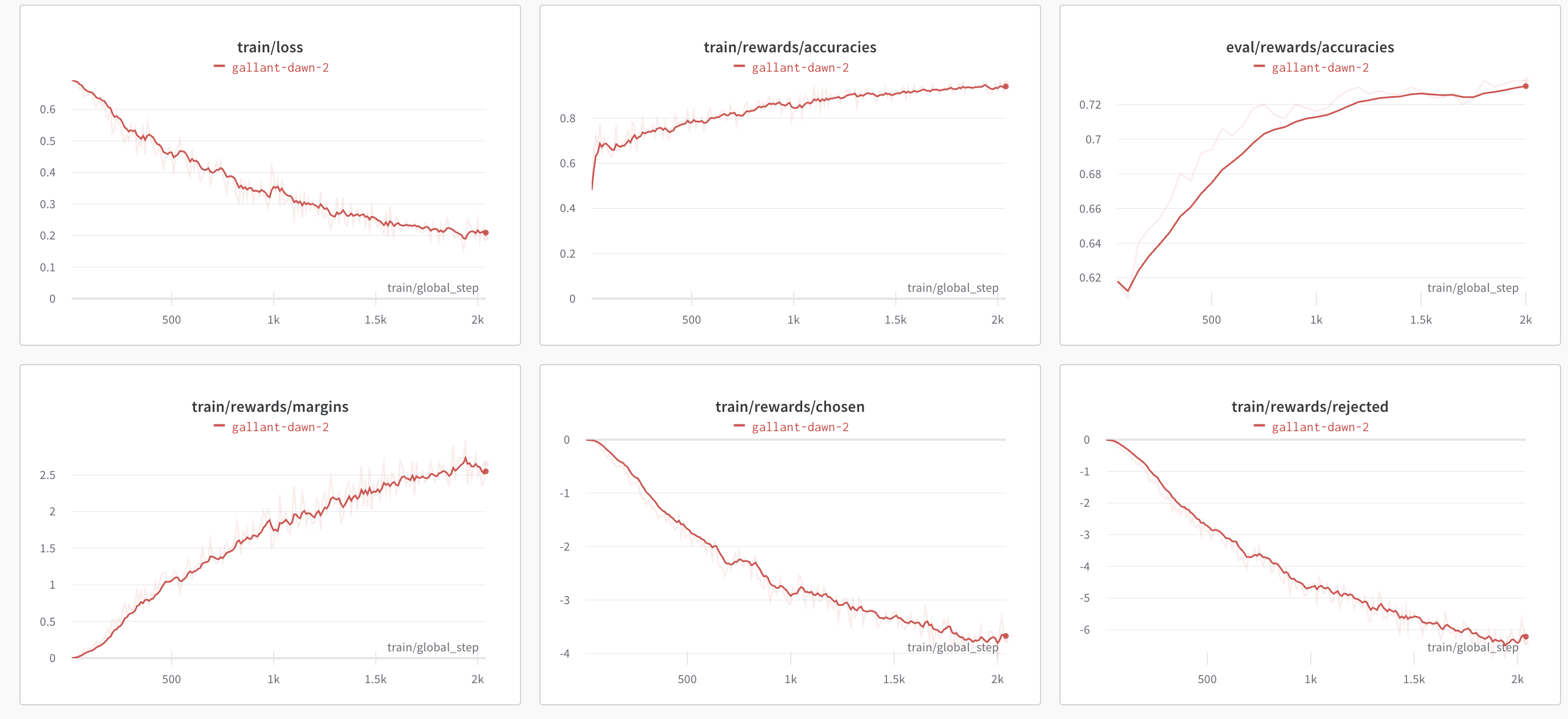
可以看到上图的情况属于: 左边变小,右边更小, 生成badcase概率大幅降低,模型整体变好。
不过可以观测到DPO相比PPO阶段的reward模型的acurracy是下降的,DPO效果相比PPO可能会下降,这可能也是大模型还没广泛应用DPO的原因。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!