大模型基础组件 - MQA和GQA
传统Transformer中的Attnetion结构是Multi-Head Attention(MHA),通过参见Attention部分的参数量可以直接提升模型的推理速度,本文将介绍 Multi-Query Attention (MQA)和 Grouped-Query Attention (GQA)两个方法。
| 优化方法 | 应用模型 |
|---|---|
| Multi-Query Attention | ChatGLM2, PaLM, Falcon |
| Grouped-Query Attention | LLaMa2 |
Multi-Query Attention
动机
首先推导在推理环节Multi-head Attention部分的计算量。
FLOPs,floating point operations,表示浮点数运算次数,衡量了计算量的大小。对于矩阵 $A(ab)$ 和 矩阵 $B(bc)$ 相乘的计算量为$2abc$次浮点数 (乘法 + 加法)
所以在Multi-head Attention部分,假设输入为 [b,s,h],(batch size, max seq len, hidden size),首先Q,K,V分别进行线性层计算,计算量为 $3*(2bshh) = 6bsh^2$。
然后QK进行Multi-head Attnetion运算,假设head num=k,计算的两个矩阵为 $[b,k,s,h/k], [b,k,h/k,s]$,计算量为 $bk2s*(h/k)s = 2bhs^2$,
继续计算在V上的加权,计算量依然为$bk2s*(h/k)s = 2bhs^2$,Attention最后还有一个线性层,计算的两个矩阵为 $[b,s,h], [h,h]$,计算量为 $b2sh*h = 2bsh^2$
所以,整体的计算量为 $6bsh^2 + 2bhs^2 + 2bhs^2 + 2bsh^2 = 8bsh^2 + 4bhs^2$ 当h>>s时候,计算量等效于$O(bsh^2)$
继续推导在推理环节Multi-head Attention部分的显存访问,包括Q,K,V,O这些输入输出为$O(bsh)$,输出的socre矩阵为$O(bhs^2)$,参数矩阵为$O(h^2)$,所以整体的显存占用为$O(bsh+bhs^2+h^2)$
现代GPU的计算量远大于带宽量,模型推理时候的吞吐太低,主要因为带宽不足,所以需要削减显存访问的次数,观察上式,最可能裁剪的就是Attention部分的参数。
方法
Multi-Head Attention,包含了多个Head,其中每个Head又包括了Query,Key,Value三个参数矩阵。
MQA让所有的Head之间 共享同一份Key和Value参数,每个头只单独保留了一份Query参数,从而大大减少Key和Value矩阵的参数量。
实验表明,在推理阶段,beam size=1的时候解码速度能提升约12倍,beam size=4时候能提升约6倍。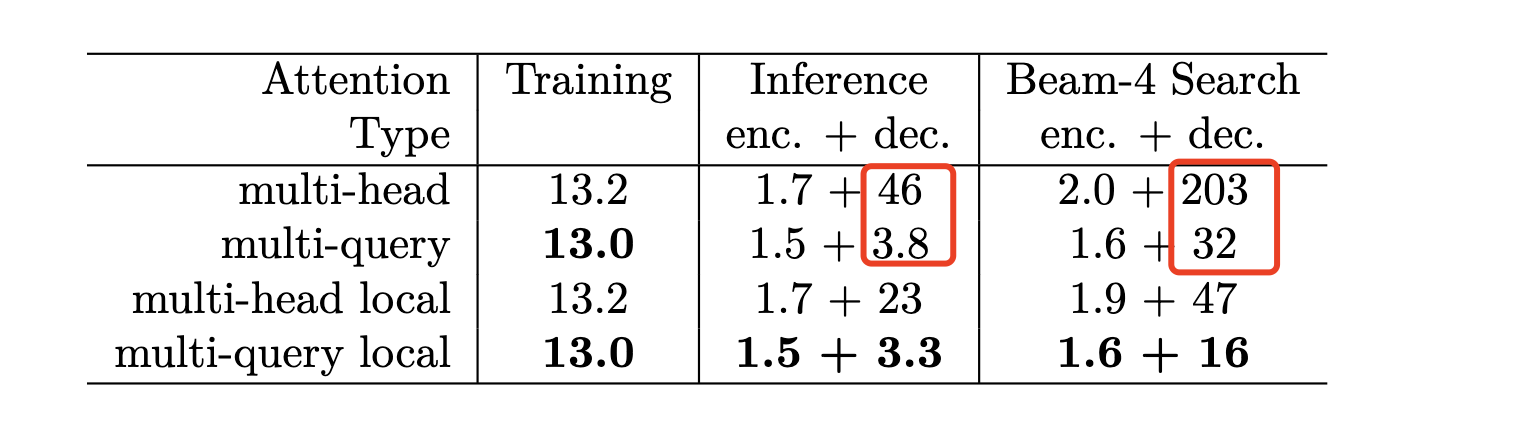
这种方式使得模型的参数大幅下降,所以模型的效果相比MHA也会略有损失。
现有模型升级
GQA[2]中提出,通过继续训练的方法,可以将一个已经训练好的MHA的模型转换成MQA的模型。大幅节省现有模型升级的成本。
具体分成两个步骤: (1) 权重转换 (2) 继续预训练让模型适应新的结构
权重转换: 将原有的K和V的参数矩阵,通过mean pool的方式合并成一个参数。这种方法相比随机初始化,随机选一个,效果都好更好。具体如下图所示:
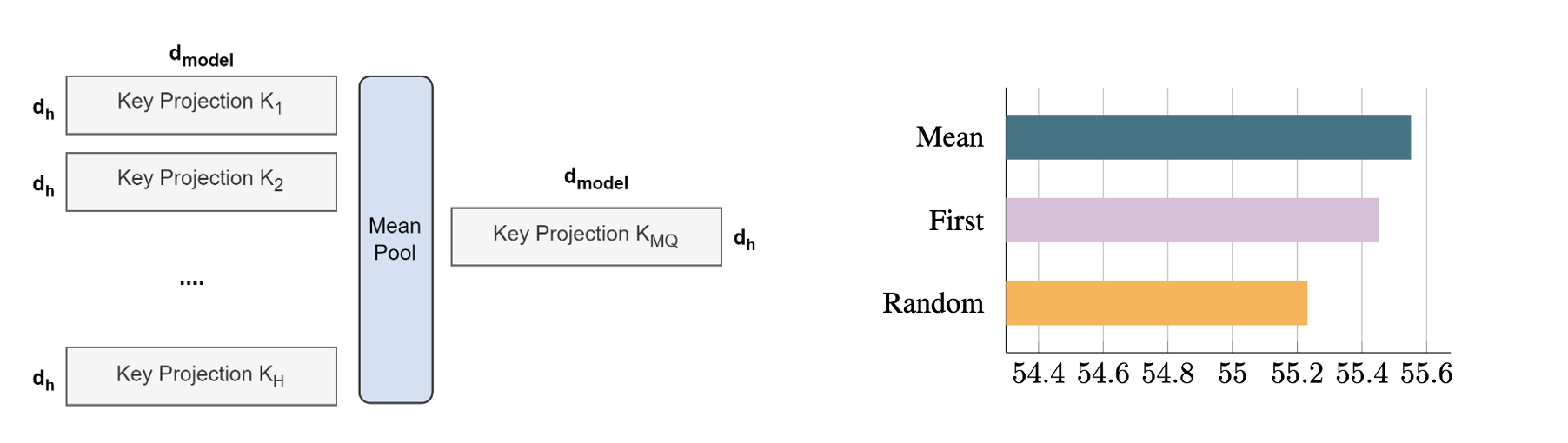
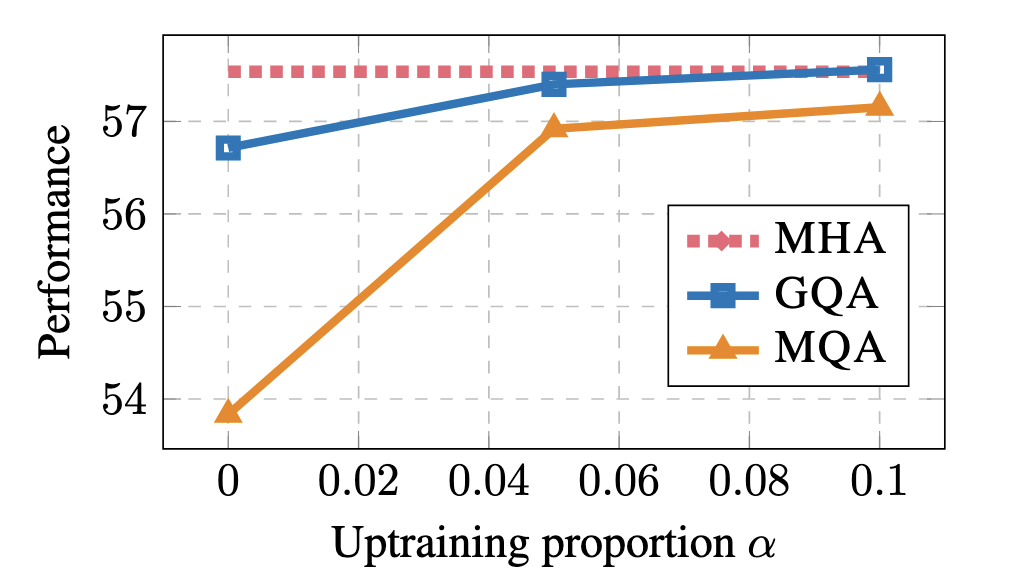
继续预训练: 实验表明,继续训练原先5%的语料就能带来巨大的提升,同时当超过10%的语料后收益就会下降。
Grouped-Query Attention
动机
Grouped-Query Attention(GQA)[2]是MQA和MHA的折中方案。从而实现相比MHA速度更快,同时性能相比MQA更好。 LLaMA2就是采用了GQA的方法。
方法
将query的头分成多个组,每个组共享同一个K,V的参数矩阵。具体如下所示: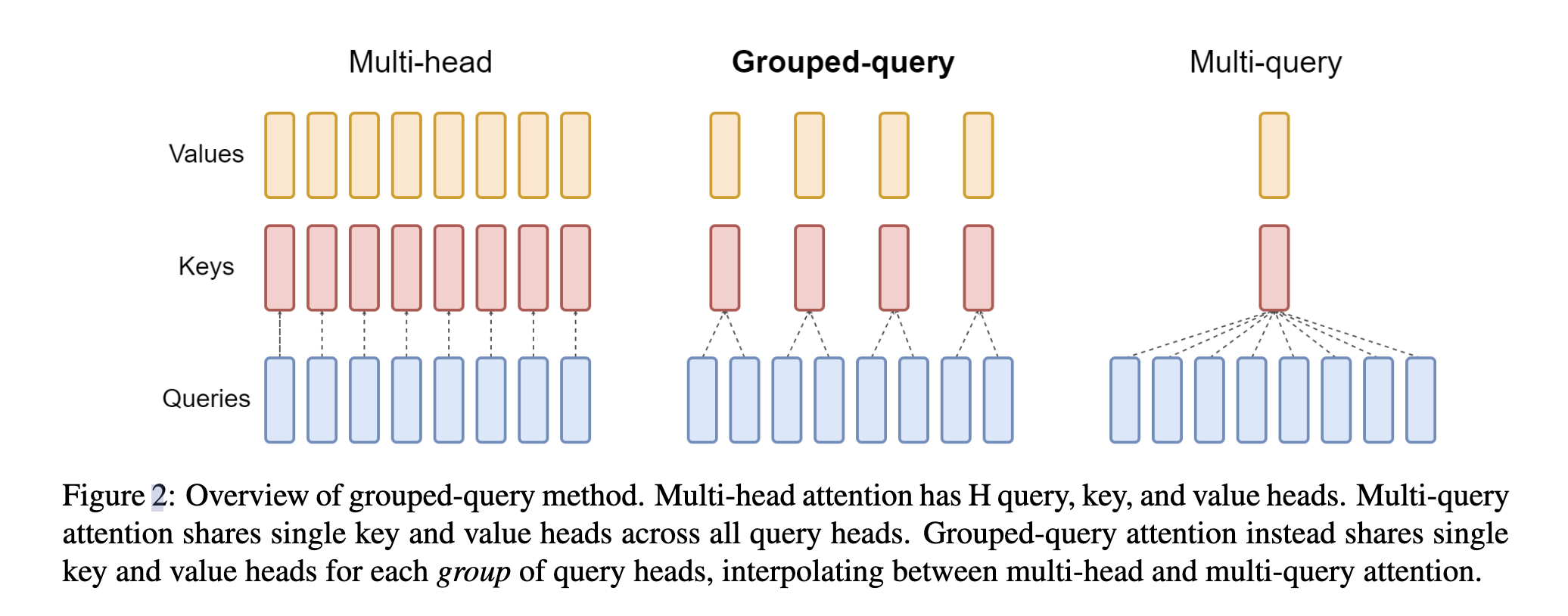
实现结果也表明,确实实现了性能和速度的平衡。当G=8的时候,效果大幅领先MQA,同时速度大幅优于MHA并于MQA接近。
当G在1-8之间,推理速度都基本与MQA相近。
现有模型升级
类似MQA中的升级思路,将原先的Multi-Head的参数进行分组,每组取均值,构成新的参数。并且继续进行5%-10%的预训练,让模型适应新的模型结构。
参考
[1]Fast Transformer Decoding: One Write-Head is All You Need
[2]GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!