TensorRT-LLM是NVIDIA官方的大模型部署方案。本文是一个初步踩坑后的笔记总结。
特性
TensorRT-LLM包括以下一系列的特性,是当前大模型部署必备神器:
- 模型转换: 提供了常见大模型示例,包括LLaMA、ChatGLM,Baichuan,Bloom
- 算子优化: 对大模型中主要算子进行了优化,包括Attention,RoPE等
- 模型量化: 支持不同级别的量化,包括fp16,bf16,int8, int4等
- 多机多卡: 支持多机多卡部署超大规模的模型
- 连续批处理: 即vLLM中的continuous batching,可大幅提高模型吞吐
- 支持Triton: 官方提供了Triton的backend,方便快速接入Triton框架
环境准备
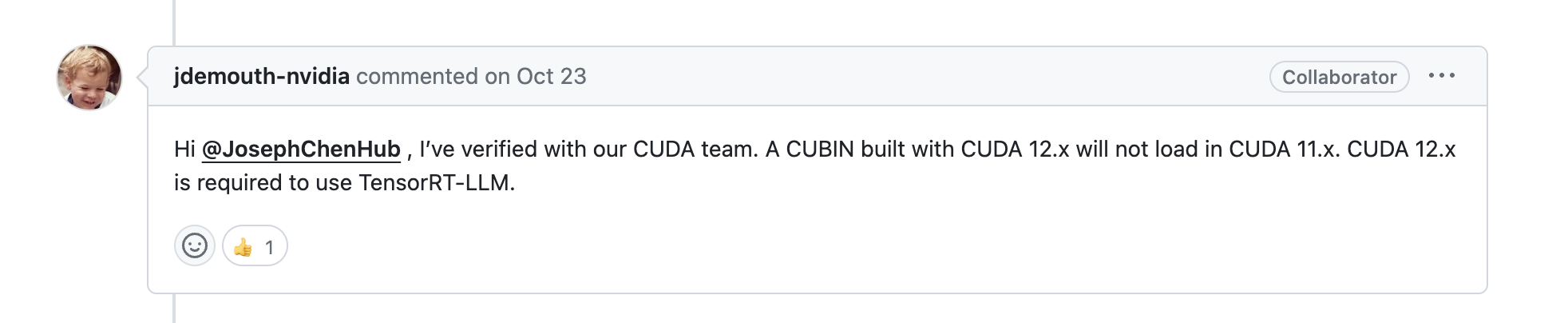
确保CUDA版本为12.x,否则先进行升级
当前已经不需要自己编译TensorRT-LLM(非常耗时),官方提供了编译好的Docker。

所以直接下载官方Triton23.10的镜像,选择内置tensorrt-llm和Python的版本
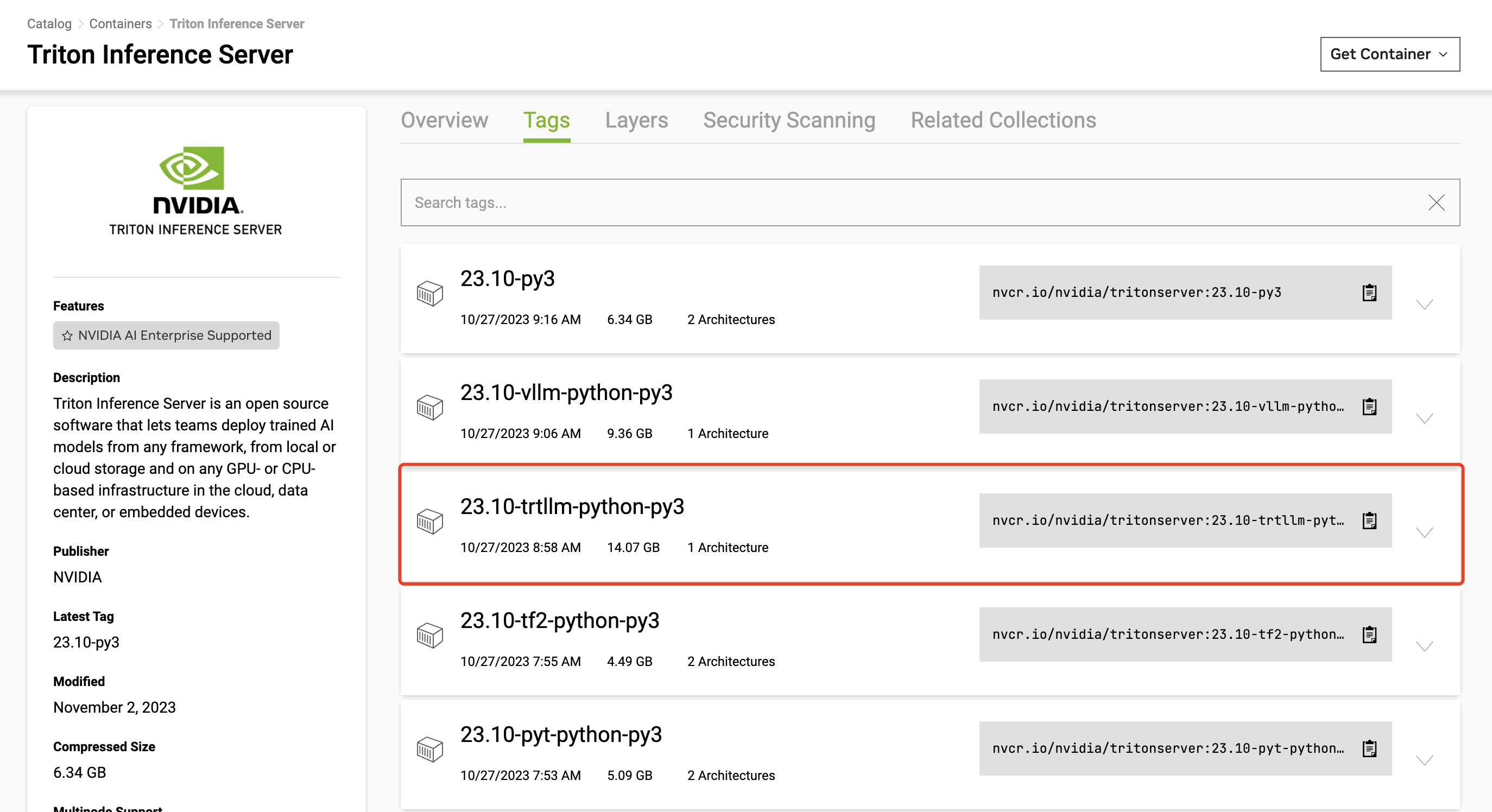
| docker pull nvcr.io/nvidia/tritonserver:23.10-trtllm-python-py3
|
启动并进入容器
1
| docker run -it --gpus all nvcr.io/nvidia/tritonserver:23.10-trtllm-python-py3 bash
|
安装TensorRT-LLM
1
2
3
4
5
6
7
| git clone https://github.com/triton-inference-server/tensorrtllm_backend.git
cd tensorrtllm_backend
git clone https://github.com/NVIDIA/TensorRT-LLM.git tensorrt_llm
pip install git+https://github.com/NVIDIA/TensorRT-LLM.git
mkdir /usr/local/lib/python3.10/dist-packages/tensorrt_llm/libs/
cp /opt/tritonserver/backends/tensorrtllm/* /usr/local/lib/python3.10/dist-packages/tensorrt_llm/libs/
|
模型转换
这里以Baichuan7B-V1-Base为例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
cd tensorrt_llm/examples/baichuan
python build.py --model_version v1_7b \
--model_dir Baichuan-7B \
--dtype float16 \
--use_gpt_attention_plugin float16 \
--use_inflight_batching \
--paged_kv_cache \
--max_input_len 32 \
--max_output_len 32 \
--max_beam_width 1 \
--tokens_per_block 32 \
--output_dir ./trt_engines/baichuan/
|

转换好之后,可以执行run.py进行初步验证
1
2
3
4
5
| python run.py --model_version v1_7b \
--max_output_len=20 \
--tokenizer_dir=Baichuan-7B \
--input_text 北京是 \
--engine_dir=./trt_engines/baichuan/
|

模型部署
下面结合triton进行模型的部署
首先准备相关文件
1
2
3
4
5
| cd /opt/tritonserver/tensorrtllm_backend
mkdir triton_model_repo
cp -r all_models/inflight_batcher_llm/* triton_model_repo/
cp tensorrt_llm/examples/baichuan/trt_engines/baichuan/* triton_model_repo/tensorrt_llm/1
cd triton_model_repo/
|
现在triton_model_repo目录的结构,如下所示:

- preprocessing: 用于encode,tokenizer将输入的prompt转换成intpu_id
- tensorrt_llm: 模型推理
- postprocess: 用于decode,tokenizer将输出的token id转换成token
- ensemble: 用来串联以上三个模型: preprocessing->tensorrt_llm->postprocess
修改preprocessing, tensorrt_llm, postprocess中的config.pbtxt
可以参考: https://github.com/triton-inference-server/tensorrtllm_backend#modify-the-model-configuration
一些注意点
- preprocessing和postprocess中,Baichuan等模型,
tokenizer_type为auto,同时需要修改中的model.py,添加trust_remote_code=True
- tensorrt_llm中,
max_tokens_in_paged_kv_cache会覆盖kv_cache_free_gpu_mem_fraction; enable_trt_overlap设置为False
- ensemble中的
max_batch_size需要与preprocessing,tensorrt_llm,postprocess相同
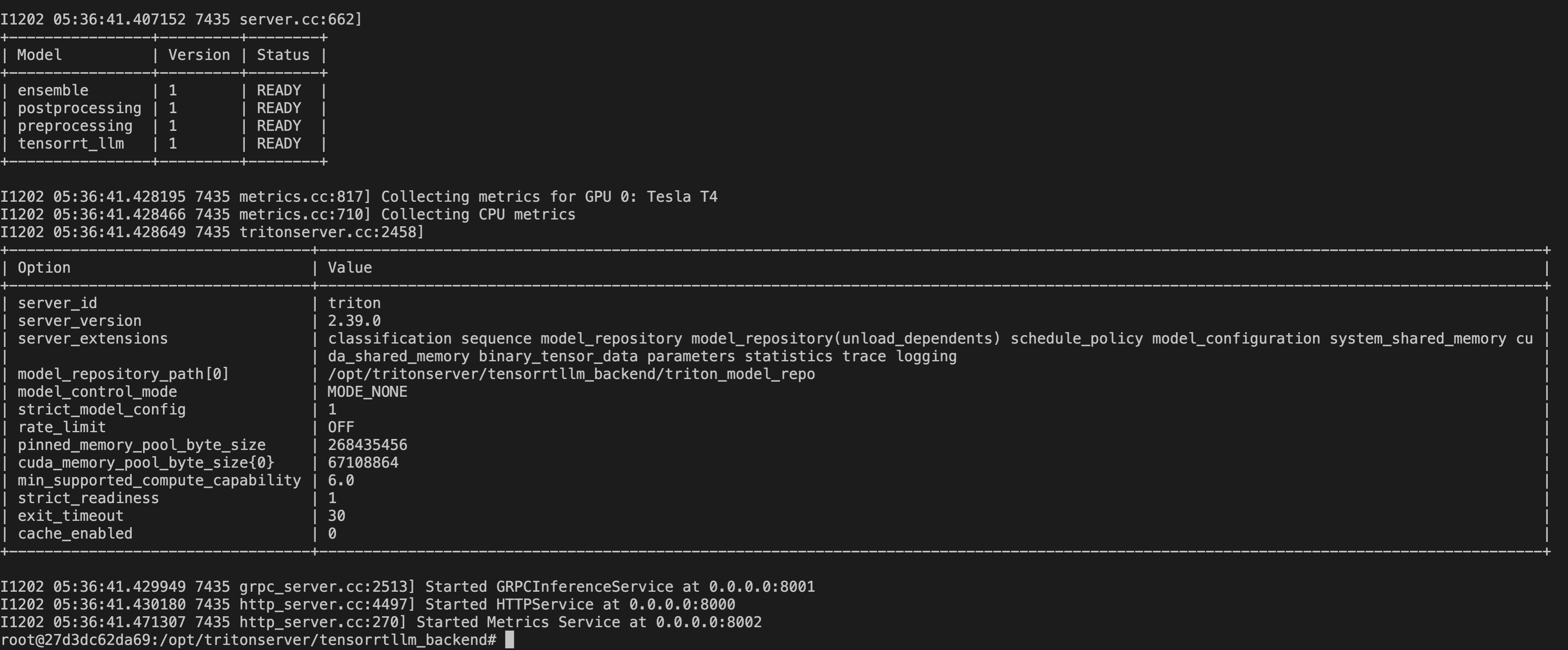
然后启动triton服务
1
| python3 scripts/launch_triton_server.py --world_size=4 --model_repo=/tensorrtllm_backend/triton_model_repo
|
模型测试
直接用curl请求ensemble的HTTP接口进行测试:
1
| curl -X POST localhost:8000/v2/models/ensemble/generate -d '{"text_input": "北京是", "max_tokens": 20, "bad_words": "", "stop_words": ""}'
|
返回json格式
1
2
3
4
5
6
7
8
| {
"model_name":"ensemble",
"model_version":"1",
"sequence_end":false,
"sequence_id":0,
"sequence_start":false,
"text_output":"北京是我国的首都,也是我国的政治中心,北京的气候类型是( )\n解答:"
}
|
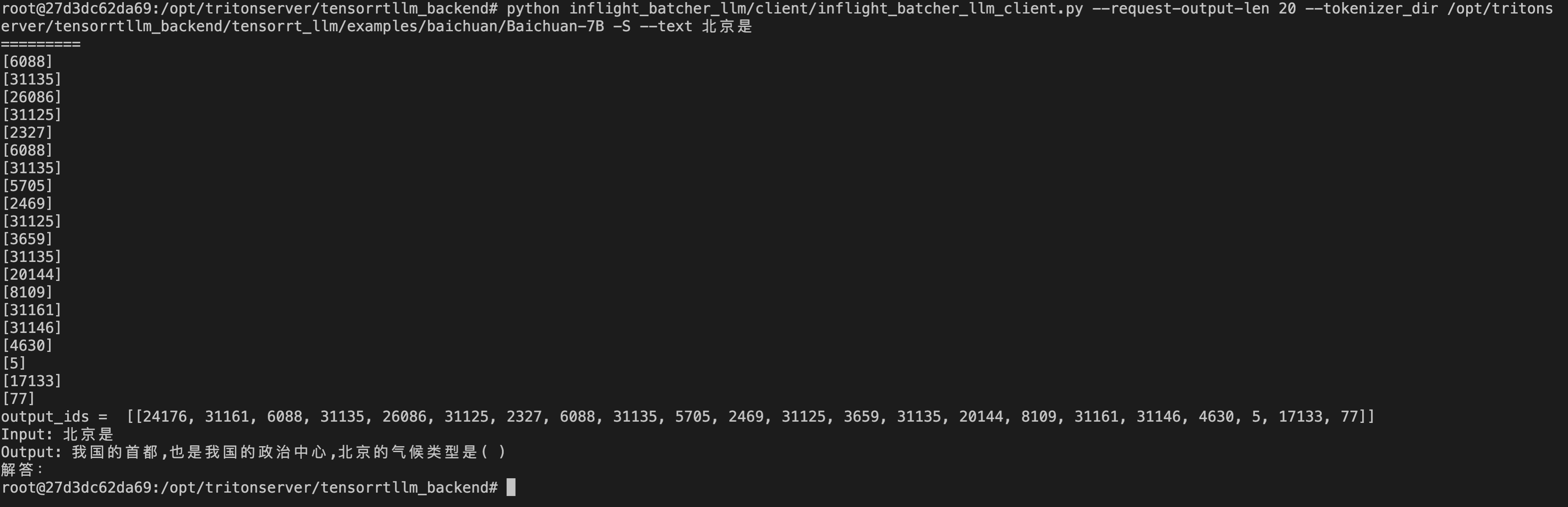
也可以只请求tensort_llm服务,自己完成预处理和后处理
1
| python inflight_batcher_llm/client/inflight_batcher_llm_client.py --request-output-len 20 --tokenizer_dir /opt/tritonserver/tensorrtllm_backend/tensorrt_llm/examples/baichuan/Baichuan-7B -S --text 北京是
|
参考