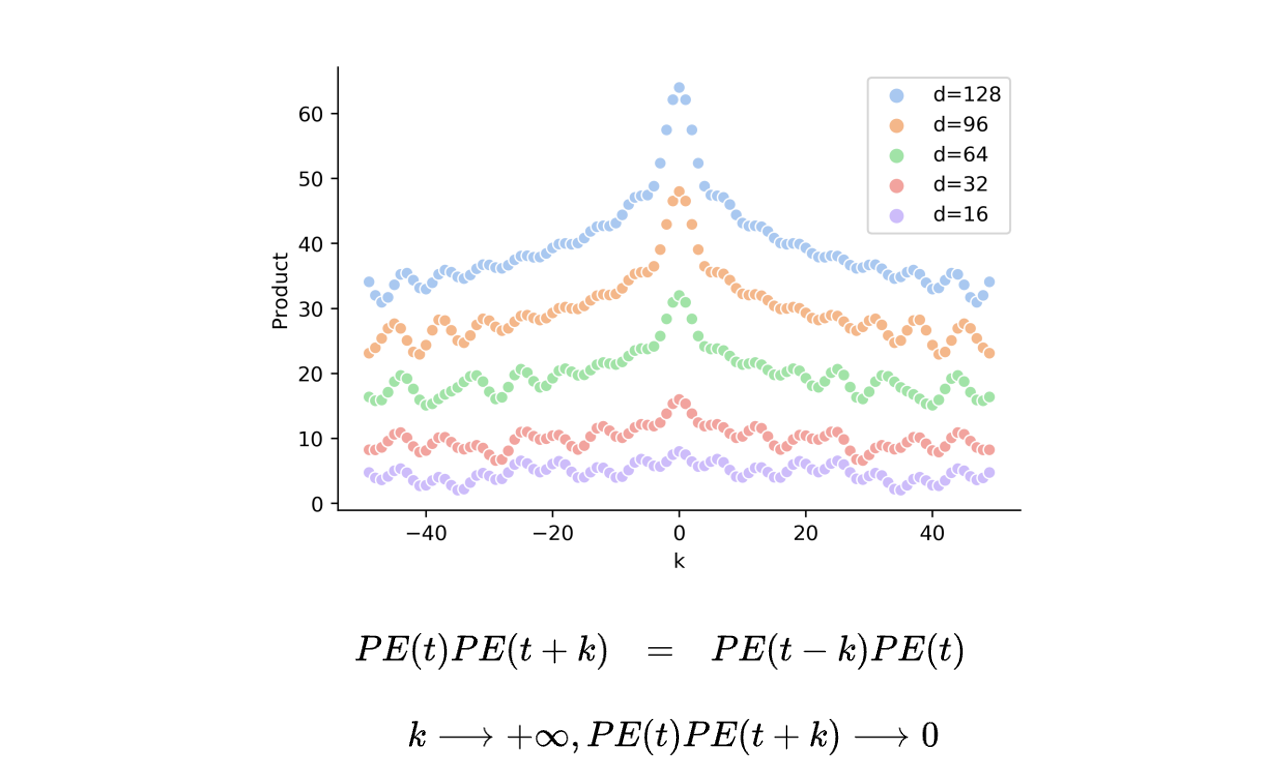
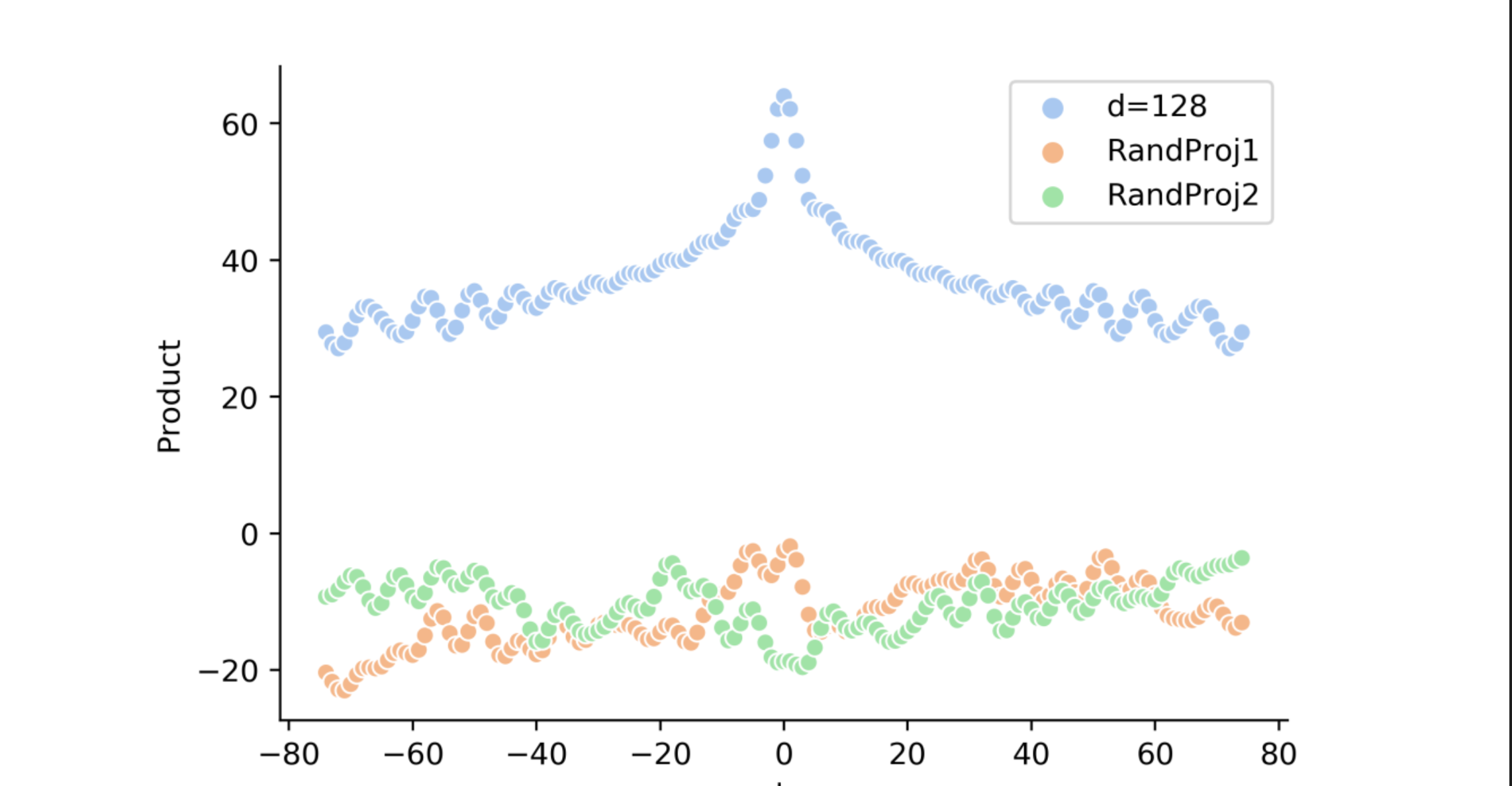
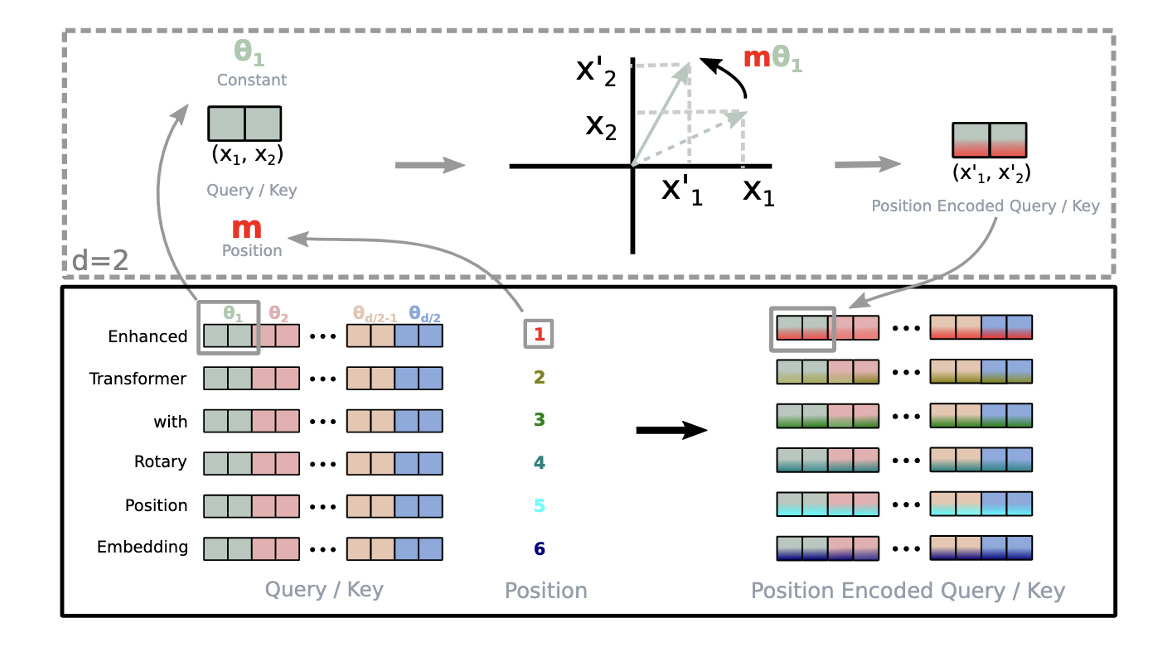
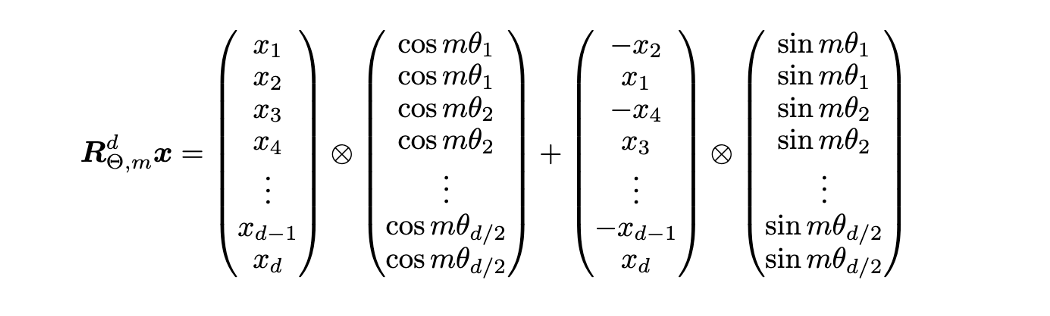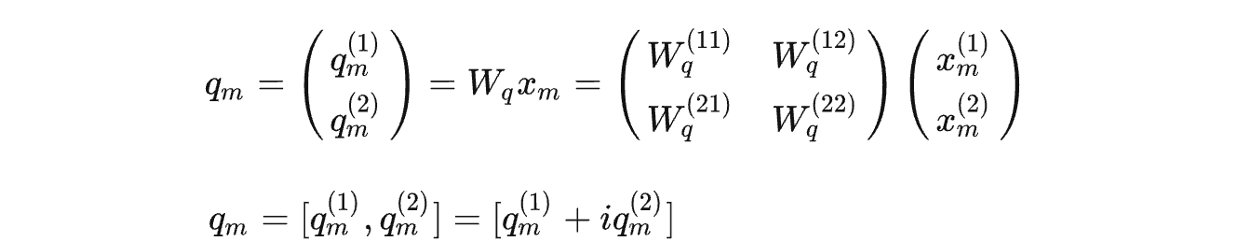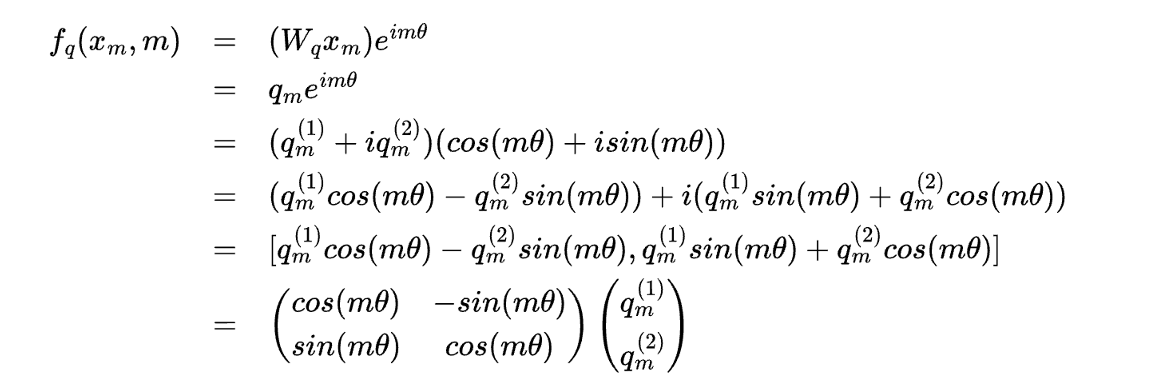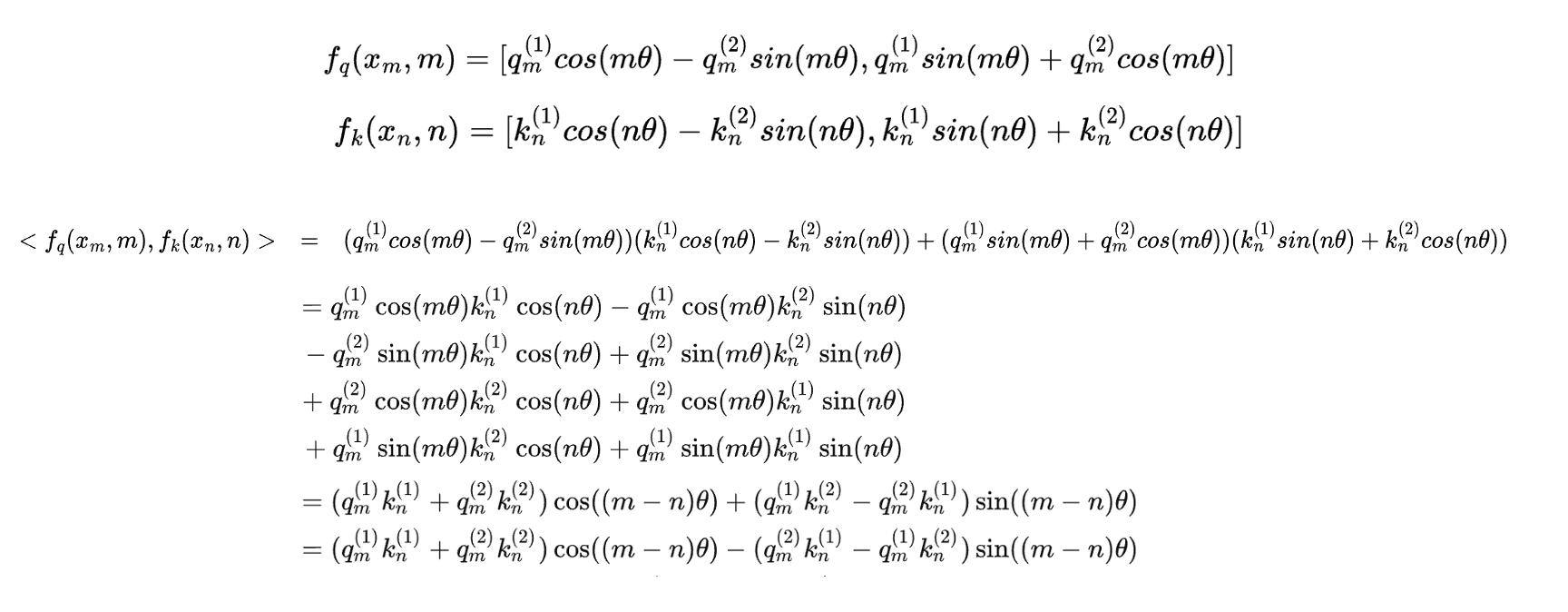# Build here to make `torch.jit.trace` work. self._set_cos_sin_cache( seq_len=max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype() )
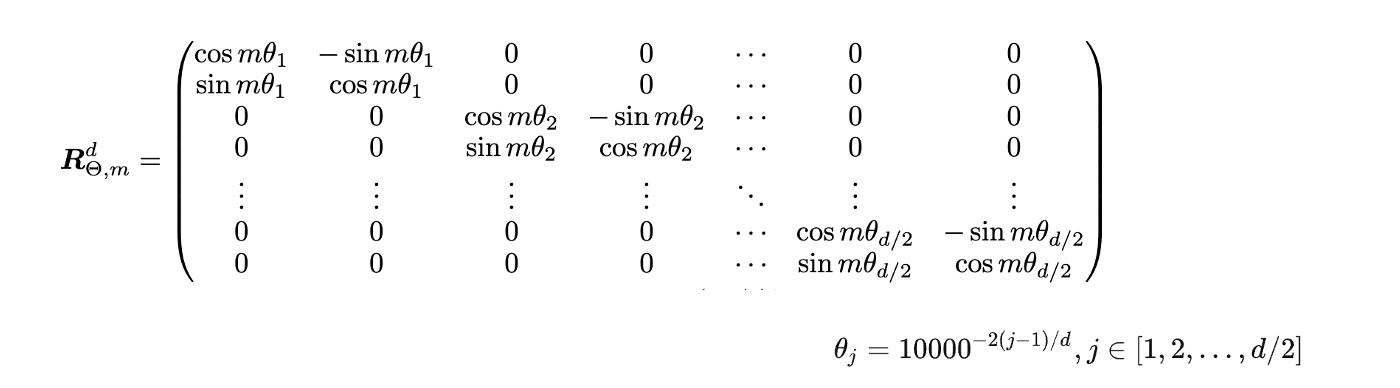
def_set_cos_sin_cache(self, seq_len, device, dtype): self.max_seq_len_cached = seq_len t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype) # 外积, m*theta freqs = torch.einsum("i,j->ij", t, self.inv_freq) # Different from paper, but it uses a different permutation in order to obtain the same calculation emb = torch.cat((freqs, freqs), dim=-1) self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(dtype), persistent=False) self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(dtype), persistent=False)
defrotate_half(x): """Rotates half the hidden dims of the input.""" x1 = x[..., : x.shape[-1] // 2] x2 = x[..., x.shape[-1] // 2 :] return torch.cat((-x2, x1), dim=-1)
defapply_rotary_pos_emb(q, k, cos, sin, position_ids): # The first two dimensions of cos and sin are always 1, so we can `squeeze` them. cos = cos.squeeze(1).squeeze(0) # [seq_len, dim] sin = sin.squeeze(1).squeeze(0) # [seq_len, dim] cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim] sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim] q_embed = (q * cos) + (rotate_half(q) * sin) k_embed = (k * cos) + (rotate_half(k) * sin) return q_embed, k_embed
# attention部分 cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len) query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
defbuild_alibi_tensor(attention_mask: torch.Tensor, num_heads: int, dtype: torch.dtype) -> torch.Tensor: """ Link to paper: https://arxiv.org/abs/2108.12409 Alibi tensor is not causal as the original paper mentions, it relies on a translation invariance of softmax for quick implementation: with l being a tensor, and a fixed value `softmax(l+a) = softmax(l)`. Based on https://github.com/ofirpress/attention_with_linear_biases/blob/a35aaca144e0eb6b789dfcb46784c4b8e31b7983/fairseq/models/transformer.py#L742 TODO @thomasw21 this doesn't work as nicely due to the masking strategy, and so masking varies slightly.
Args: Returns tensor shaped (batch_size * num_heads, 1, max_seq_len) attention_mask (`torch.Tensor`): Token-wise attention mask, this should be of shape (batch_size, max_seq_len). num_heads (`int`, *required*): number of heads dtype (`torch.dtype`, *optional*, default=`torch.bfloat16`): dtype of the output tensor """ batch_size, seq_length = attention_mask.shape closest_power_of_2 = 2 ** math.floor(math.log2(num_heads)) base = torch.tensor( 2 ** (-(2 ** -(math.log2(closest_power_of_2) - 3))), device=attention_mask.device, dtype=torch.float32 ) powers = torch.arange(1, 1 + closest_power_of_2, device=attention_mask.device, dtype=torch.int32) slopes = torch.pow(base, powers)
# Note: alibi will added to the attention bias that will be applied to the query, key product of attention # => therefore alibi will have to be of shape (batch_size, num_heads, query_length, key_length) # => here we set (batch_size=1, num_heads=num_heads, query_length=1, key_length=max_length) # => the query_length dimension will then be broadcasted correctly # This is more or less identical to T5's relative position bias: # https://github.com/huggingface/transformers/blob/f681437203baa7671de3174b0fa583c349d9d5e1/src/transformers/models/t5/modeling_t5.py#L527 arange_tensor = ((attention_mask.cumsum(dim=-1) - 1) * attention_mask)[:, None, :] alibi = slopes[..., None] * arange_tensor return alibi.reshape(batch_size * num_heads, 1, seq_length).to(dtype)