中文文本纠错调研
前言
文本纠错是一项自然语言处理的基础性工作,是搜索引擎,问答/对话系统,输入法等应用中必不可少的前置模块,纠错的质量对后续的处理非常重要。本文将对中文文本纠错进行系统调研,包括错误类型整理、工业界和学术界的常用方法以及还存在哪些问题。
任务定义
系统/模型的输入为原始序列$X = (x_{1},x_{2},..,x_{n})$,输出为纠错后的序列 $Y = (y_{1},y_{2},..,y_{m})$;
注意这里$X$可能已经是完全正确的序列,所以$X$可能与$Y$相同。
系统/模型需要支持多种粒度的序列,包括:字词、短语、句子、短文。
错误类型
只有明确有哪些错误类型才能设计出良好的纠错系统,在参考了多个纠错系统的需求设计方案以及中文自身的病句类型划分后,暂且将纠错类型划分成三类:字词错误、句法错误和语义错误,具体如下:
| 错误类型 | 错误示例 | |
| 字词错误 | 同音词 | 米月传 -> 芈月传 ; 渡假 -> 度假 |
| 模糊音 | 胡建 -> 福建 ; 东北银 -> 东北人 | |
| 形近词 | go语音 -> go语言 | |
| 混拼音 | xingfu -> 幸福 ; sz -> 深圳 | |
| 句法错误 | 字词缺失 | 自然语处理 -> 自然语言处理 |
| 字词冗余 | 自然语言处处理 -> 自然语言处理 | |
| 字词乱序 | 首个开发的空间站 -> 开发的首个空间站 | |
| 搭配不当 | 生活水平改善 -> 生活水平提高 | |
| 结构混乱 | 靠的是...取得的 -> 靠的是... / 是...取得的 | |
| 语义错误 | 知识错误 | 中国的首都是南京 -> 中国的首都是北京 | 表意不明 | 让赵乡长本月15日前去汇报 -> 前 OR 前去 |
| 逻辑错误 | 防止这类事故不再发生 -> 防止这类事故再发生 | |
整体处理难度上:字词错误 < 句法错误 < 语义错误。
目前的研究集中在字词错误和简单的句法错误上,较少涉及语义错误。
工业界方案
工业界纠错系统一般要求能在5ms以内给出结果,所以工业界一般采用基于机器学习/简单神经网络的检索式的系统,包括检错和纠错两个模块,依托大规模的历史对齐语料来构建检错数据集并挖掘混淆矩阵以实现检索式纠错。
| 系统名称 | 技术特色 | 支持的纠错错误类型 |
|---|---|---|
| pycorrector 开源项目 |
基于规则的检索系统 基于深度学习的NMT架构 基于BERT的序列标注纠错 |
字词错误 句法错误 |
| 通用中文纠错系统 百度 |
基于机器学习的检索式系统 基于深度学习的NMT架构 |
字词错误 句法错误 语义错误 |
| 保险垂域中文纠错 平安 |
特定领域低资源 基于机器学习的检索式系统 |
字词错误 句法错误 语义错误 |
pycorrector (开源项目,2021)
重点解决其中的谐音、混淆音、形似字错误、中文拼音全拼、语法错误带来的纠错任务。
这是目前中文最佳的纠错开源项目,包括基于规则和深度学习的两类方法,并且在持续的更新与维护。
- 基于规则的方法包括错误检测和错误纠正两个步骤,错误检测部分包括字粒度和词粒度,错误纠正部分则是用预制的混淆矩阵进行替换,选择出语言模型最佳的候选词。
- 基于深度学习的方法主要包括seq2seq的方案(RNN或者Transformers),以及基于BERT的序列标注对应纠错。
该仓库集成了中文文本纠错的公开数据集语料:
集成的模型:
测评结果:
可以看到目前macbert是效果最佳的,这里MacBERT是一个与BERT结构完全一致的语言模型,在其使用在预训练中使用“相近”的单词替换原文中的单词而非直接使用[MASK],缩小训练前和微调阶段之间的差距。不过该模型只能处理输入输出等长的纠错任务,与后文的Soft-MASK BERT一样,具有一定局限性。
通用中文纠错系统(百度,2019)
整体上包括检索式架构以及NMT架构两种方案,不过按照文章篇幅推测,百度应该主要就是检索式的架构。对于检索式的架构将纠错流程分解为:错误检测、候选召回、纠错排序三个步骤。并通过引入语言知识、上下文理解和知识计算以提升不同类型错误的解决能力。
错误检测:抽象成序列标注任务,所以模型基本结构为“上下文表示+CRF”
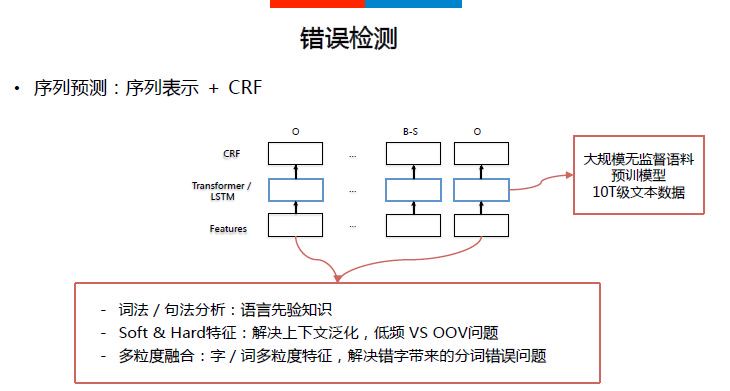
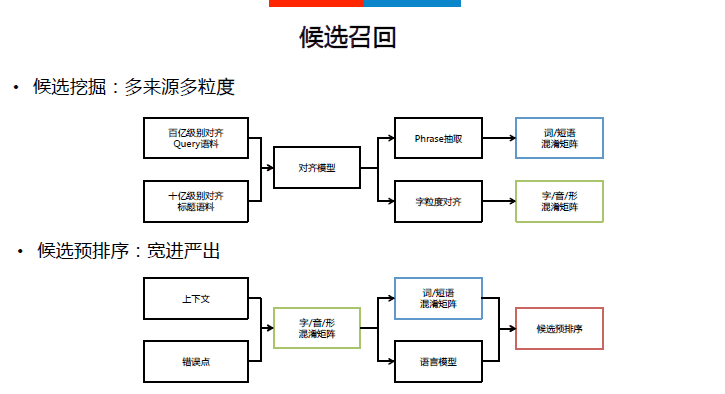
候选召回:从基于历史的对齐语料挖掘的混淆矩阵中召回可能的候选句子
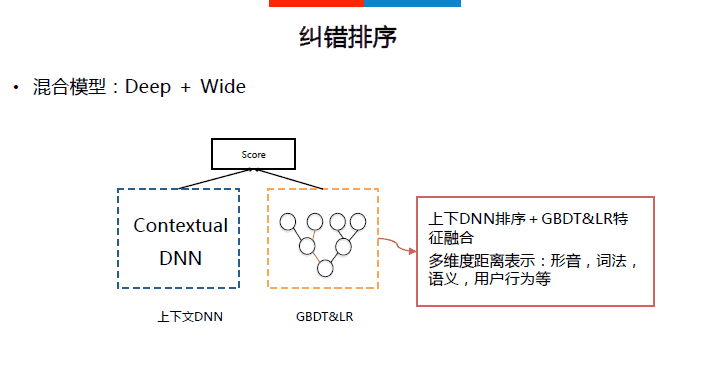
纠错排序:基于Deep&Wide的深度模型对候选词进行排序
百度的检索式方法与pycorrector基于规则的检索式方法一致,不过百度在检错和纠错(召回+排序)都是用了机器学习/深度学习的模型来实现,而pycorrector则用了纯规则的方法来计算。
该系统在百度纠错开放平台进行了实际的落地应用。
保险垂域中文纠错(平安,2019)
调研结论:
① 从百度纠错系统和IJCNLP第一名使用方法来看,当具有充足的标注语料时,将LSTM+CRF这种序列标注方式用来进行错误位置检测是一个比较好的方法,但当标注语料有限时,该种方法难以应用落地;
② 基于机器翻译的纠错方法是目前业界及学术界关注的焦点,寿险场景也可以尝试使用NMT的方法来测试效果,然而该技术落地的条件是仍然需要大量的标注数据。
该系统主要是特定的垂直领域以及低资源的场景下的方案,系统采用了检索式的纠错方案,将纠错流程分解为错误检测→候选召回→打分排序三个步骤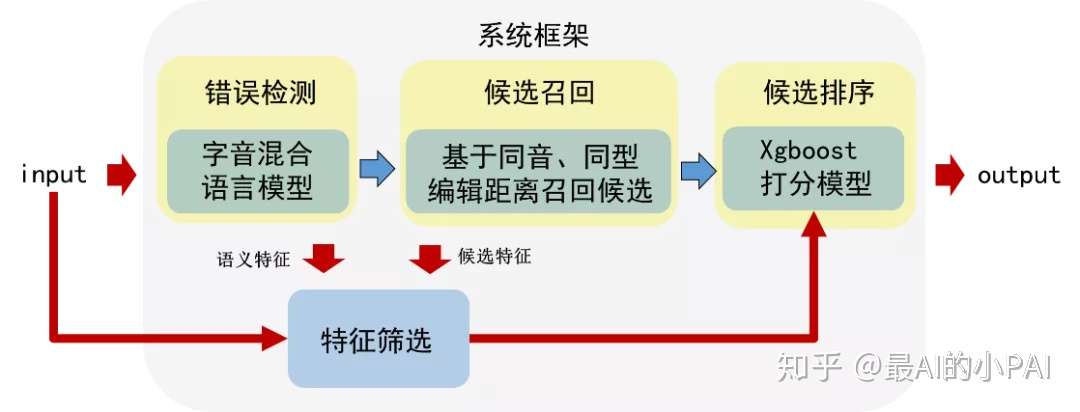
- 错误检测: 因为低资源,所以没有直接采用LSTM+CRF的序列标准模型,而是在语言表示中引入了拼音的先验特征。语言表示采用基础的Word2Vec。
- 候选召回: 基于倒排索引字典的编辑距离进行召回,并采用分层的思想优化了索引的空间。
- 打分排序:构建人工特征(基础特征、差异特征以及语义特征)利用机器学习的方法来进行排序。
该系统在平安人寿的问答机器中进行了实际的落地应用。
学术界方案
学术界一般将纠错问题建模成seq2seq的翻译任务,所以一般采用端到端的生成式模型。随着BERT的出现也开始将其引入,来处理输入输出等长的纠错任务。
| 模型 | 技术特色 | 支持的纠错类型 |
|---|---|---|
| Seq2Seq(RNN) Transformer |
端到端的Encoder-Decoder模型 | 字词错误 句法错误 语义错误 |
| BERT-Finetune Soft-Masked BERT |
利用BERT的MLM特定进行纠错 只能处理输入输出等长的纠错任务 |
字词错误(部分) 句法错误(部分) |
Transformer-NMT (NLPCC2018冠军方案,网易有道)
模型简介
整个模型分层3个层次:预处理->识别和纠正->模型集成
- 预处理:使用一个简单的5-gram语言模型去除大部分的简单表面拼写错误(字词错误)
- 识别与纠正:使用Transformer中的编码解码模型来处理难度较大的错误(句法错误)
- 模型集成:如下图所示,spelling checking就是第一阶段预处理,在识别与纠正阶段训练了基于字和sub-word的两个模型,通过不同的组合方式构建了5个模型;给定一个输入,对5个输出按照5-gram的语言模型进行打分,选择最高的结果作为最后的输出。

代码: 暂无开源的代码
Soft-Masked BERT (ACL2020,字节跳动)
论文:Spelling Error Correction with Soft-Masked BERT
注意该模型只能处理输入序列和输出序列等长度的纠错场景!

模型简介:
整个模型包括检错网络和改错网路:
- 检错网络是一个简单的Bi-GRU+MLP的网络,输出每个token是错字的概率
- 改错网络是BERT模型,创新点在于,BERT的输入是原始Token的embbeding和 [MASK]的embbeding的加权平均值,权重就是检错网络的概率,这也就是所谓的Soft-MASK,即 $e_{i} = p_{i}*e_{mask} + (1-p_{i})*e_{i}$ 。极端情况下,如果检错网络输出的错误概率是1,那么BERT的输入就是MASK的embedding,如果输出的错误概率是0,那么BERT的输入就是原始Token的embedding。
在训练方式上采用Multi-Task Learning的方式进行,$L = λ · L_{c} + (1 − λ) · L_{d} $,这里$λ$取值为0.8最佳,即更侧重与改错网络的学习。
模型结果:
该结果是句子级别的评价结果,Soft-MASK BERT在两个数据集上均达到了新的SOTA,相比仅是有BERT在F1上有2-3%的提升。
该模型处理错误的情况,主要是以下两类错误:
- 模型没有推理能力不能处理逻辑错误:他主动拉了姑娘的手, 心里很”高心”, 嘴上故作生气 -> 他主动拉了姑娘的手, 心里很”高兴”, 嘴上故作生气
- 模型缺乏世界知识不能处理知识错误:芜湖: 女子落入”青戈江”,众人齐救援 -> 芜湖: 女子落入”青弋江”,众人齐救援
代码:
该工作没有官方开源,民间版本:
Dynamic Connected Networks (ACL2021,哈工大&讯飞)
论文:Dynamic Connected Networks for Chinese Spelling Check
论文还没有放出来,不过在宣传稿中表明已经达到了新的SOTA
中文拼写纠错任务(CSC)主要针对中文文本中出现的拼写错误进行检测和纠正。目前关于中文拼写纠错任务的最新研究都是采用基于BERT的非自回归模型。非自回归模型的输出独立假设使BERT模型不能很好地学到输出汉字之间的依赖关系,产生输出语句不连贯的问题。为了解决上述问题,我们提出了一个全新的动态连接网络(DCN),先通过拼音候选生成器产生合适的候选,再通过基于Attention机制的网络对两个相邻汉字的依赖关系进行建模。实验表明,我们提出的DCN方法在三个人工标注的测试集上都取得了当前最好的效果。
该论文的宣传稿有配套的演示系统,看起来功能非常强大!类似中文版本的Grammarly!
http://202.85.216.21:8095/review
具体包含了拼写纠错,语法纠错,标点纠错,实体纠错,搭配纠错,句子润色等9大类。
不过我自己测试的结果来看,还是有很多情况不能处理,如下
历史其他模型
- (爱奇艺) FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm 论文 / 代码
未来方向与挑战
- 如果有足够的对齐语料,可以继续沿Transformer的编码解码器思路,并且引入基于预训练的Seq2Seq模型,例如GPT,BART等
- 模型需要支持热更新,支持时事热点中的新词,例如当下热点的”传闻中的成仙仙” -> “传闻中的陈芊芊”
- 对于复杂的句法错误以及语义中的知识性错误、逻辑性错误、表意不明还还不能有效进行处理
参考文献
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!