(Gitchat备份)构建单机千万级别的微博爬虫系统
UPDATE
整个项目的代码已完全在Github开源:WeiboSpider
一站式的科研数据服务平台socialsensor.top 已经全面上线!! 数据获取,数据开发,数据应用点点鼠标即可实现,欢迎交流合作👏👏👏
Gitchat地址: https://gitbook.cn/books/5b651e4b5f339e0e06733834/index.html
1. 前言
这是本人第一次做Gitchat,非常荣幸能够将我这段时间对微博数据的抓取工作整理成这篇文章,分享给大家。最后,我也会讲述一下我对于爬虫的理解,以及爬虫工程师,这个大数据时代站在数据最源头的人,工作是什么样的,未来有什么发展。
2. 微博的价值
微博是中国最早兴起的自媒体平台,理念就是人人都是自媒体,人人都可以在这里发表自己的观点。到现在微博已经成为了官方,明星等“新闻发布“的第一阵地,比如政府发条微博向社会通报某件社会事件的进展情况,明星则悄咪咪的发条微博宣布自己的恋情,瞬间微博的服务器表示自己扛不住了!!
当然,对于我们普通人,也常会发微博,或者转发,评论来表达自己对于社会事件的观点,也会来表现自己生活的日常,或开心,或吐槽。
更为重要的是什么呢,微博不同于QQ空间,不同于微信朋友圈,不需要对方加你,也不需要你关注对方,你就可以看到对方的全部动态,个人信息!。所以,微博变成了唯一一个可以爬的社交媒体平台。
2.1 微博数据维度
微博数据可以分成:微博数据,用户数据,用户关系数据,评论数据 和 转发数据
2.1.1 微博数据
微博数据,就是微博最基本的语料数据。比如下面这条微博:

能抓取到的数据维度包括:
| 字段 | 说明 |
|---|---|
| _id | 微博id |
| user_id | 这则微博作者的ID |
| content | 微博的内容 |
| created_at | 微博发表时间 |
| repost_num | 转发数 |
| comment_num | 评论数 |
| like_num | 点赞数 |
| tool | 发布微博的工具 |
| image_url | 微博中图片的URL,注意如果是组图会只抓取第一张 |
| video_url | 微博中视频的URL |
| location_map_info | 定位的经纬度信息 |
| origin_weibo | 原始微博,只有转发的微博才有这个字段 |
| crawl_time | 抓取时间戳 |
2.1.2 用户数据
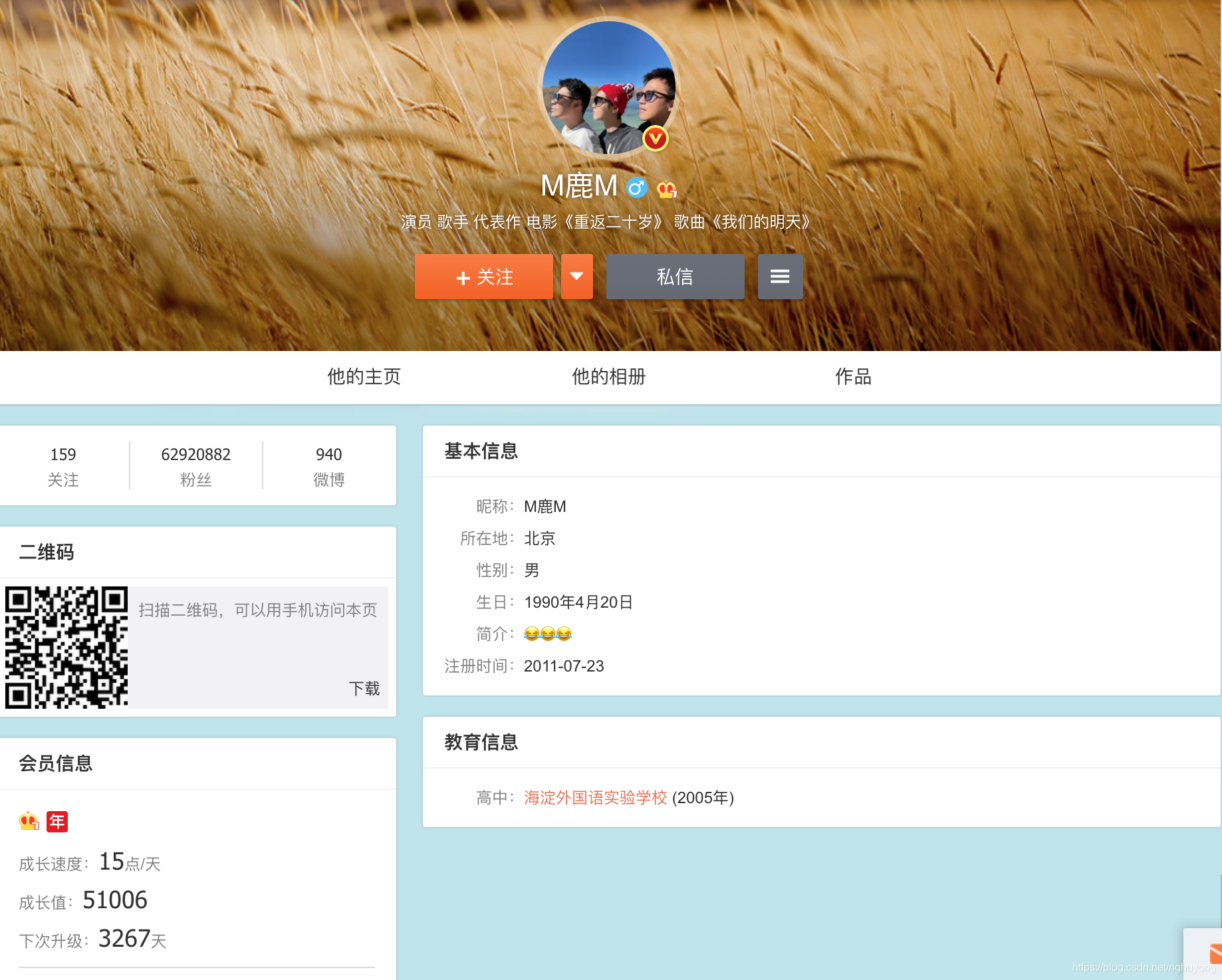
能抓取到的数据维度包括:
| 字段 | 说明 |
|---|---|
| _id | 用户的ID,可以作为用户的唯一标识 |
| nick_name | 昵称 |
| gender | 性别 |
| province | 所在省 |
| city | 所在市 |
| brief_introduction | 个人简介 |
| birthday | 生日 |
| tweets_num | 微博发表数 |
| fans_num | 粉丝数 |
| followers_num | 关注数 |
| sex_orientation | 性取向 |
| sentiment | 感情状况 |
| vip_level | 会员等级 |
| authentication | 认证情况 |
| education | 教育经历 |
| work | 工作经历 |
| person_url | 用户首页链接 |
| labels | 用户标签,用逗号分割 |
| crawl_time | 抓取时间戳 |
2.1.3 评论数据
对于一条微博的评论数据
能抓取到的数据维度包括:
| 字段 | 说明 |
| :—: | :—-: |
| _id | 评论的id |
|comment_user_id|评论的用户ID|
|weibo_id|weibo的ID|
|content|评论内容|
|created_at| 评论创建时间|
|crawl_time|抓取时间戳|
2.1.4 转发数据
对于一条微博的转发数据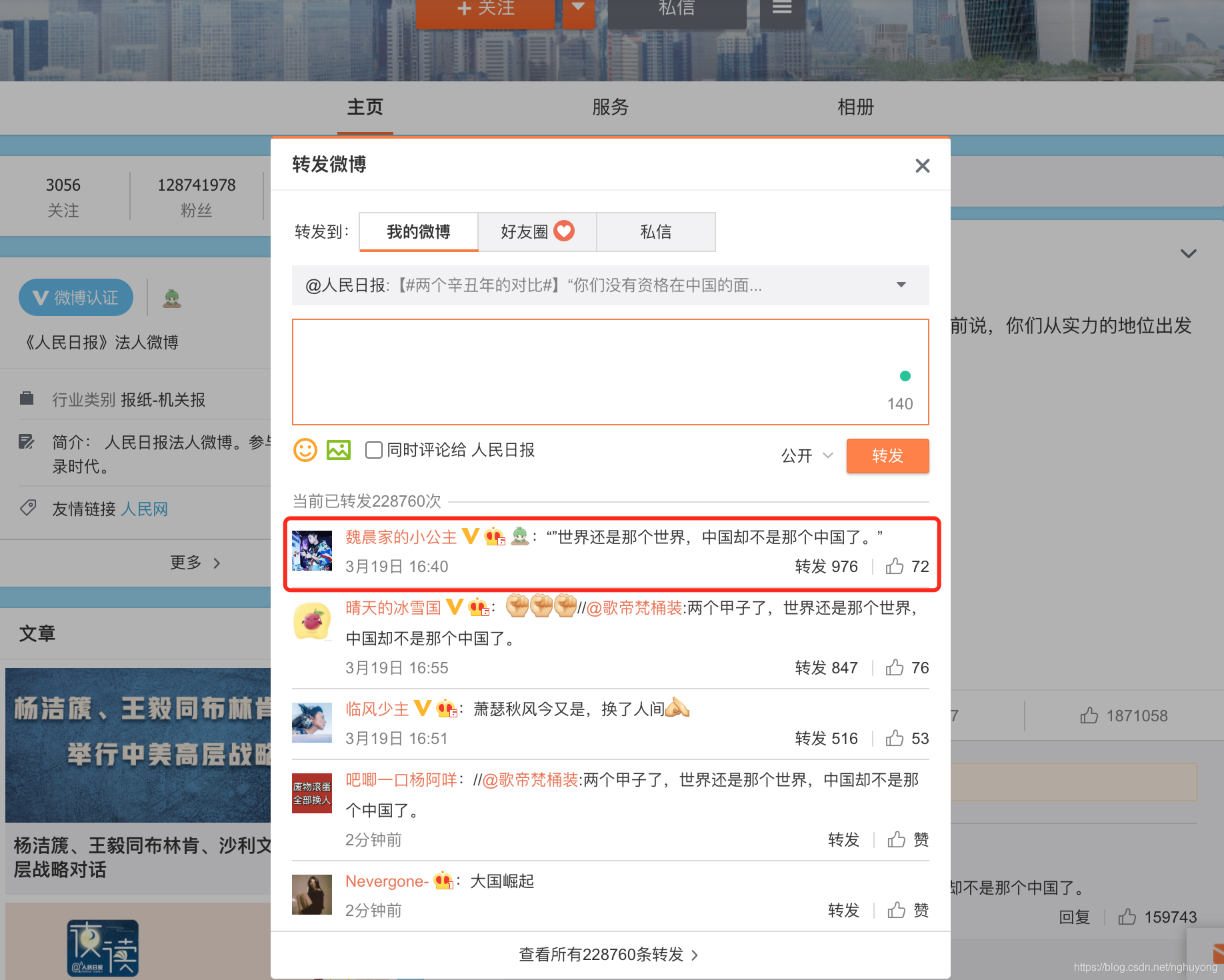
能抓取到的数据维度包括:
| 字段 | 说明 |
|---|---|
| _id | null |
| crawl_time | 抓取时间戳 |
| weibo_id | 被转发weibo的ID |
| user_id | 转发用户的ID |
| content | 转发的评论内容 |
| created_at | 转发时间 |
2.1.5社交关系
也就是用户之间的关注情况,其实只需要维护一张关注表即可,因为粉丝关系,就是反向的关注关系。

能抓取到的数据维度包括:
| 字段 | 说明 |
|---|---|
| _id | 用户关系id |
| fan_id | 关注者的用户ID |
| follower_id | 被关注者的用户ID |
| crawl_time | 抓取时间戳 |
这其实也就是一个有方向的箭头。
2.2 数据金矿
正是因为由以上这些数据维度,所以微博语料是一个非常有价值的数据金矿,在上面可以完成多种的分析和挖掘。
举一个商业分析的例子,比如你要在中国市场投放转基因的食品,你就可以根据转基因为关键词来搜索微博,对搜索结果进行情感分类,来判断中国民众对于转基因的持有态度,是支持还是反对,支持的人,是什么地区,是什么学习,同样反对的人呢,这样你就可以针对性的来投放自己产品。
再比如,其实可以通过微博来评价明星手机代言的效果。比如鹿晗代言了vivo手机,那么你就可以抓取鹿晗粉丝是什么手机,并且有没有原先不是vivo,后来变成了vivo的现象,以此来评测。
当然,还有很多很多,数据只有放在有想法的人手里才有价值。下面我们就要讨论以下,如何来抓数据了。
3. 微博爬虫
3.1 站点分析
目前微博一共有三个站点,分别是WAP站,移动站,Web站
WAP站: weibo.cn
移动站: m.weibo.com
网页站: weibo.com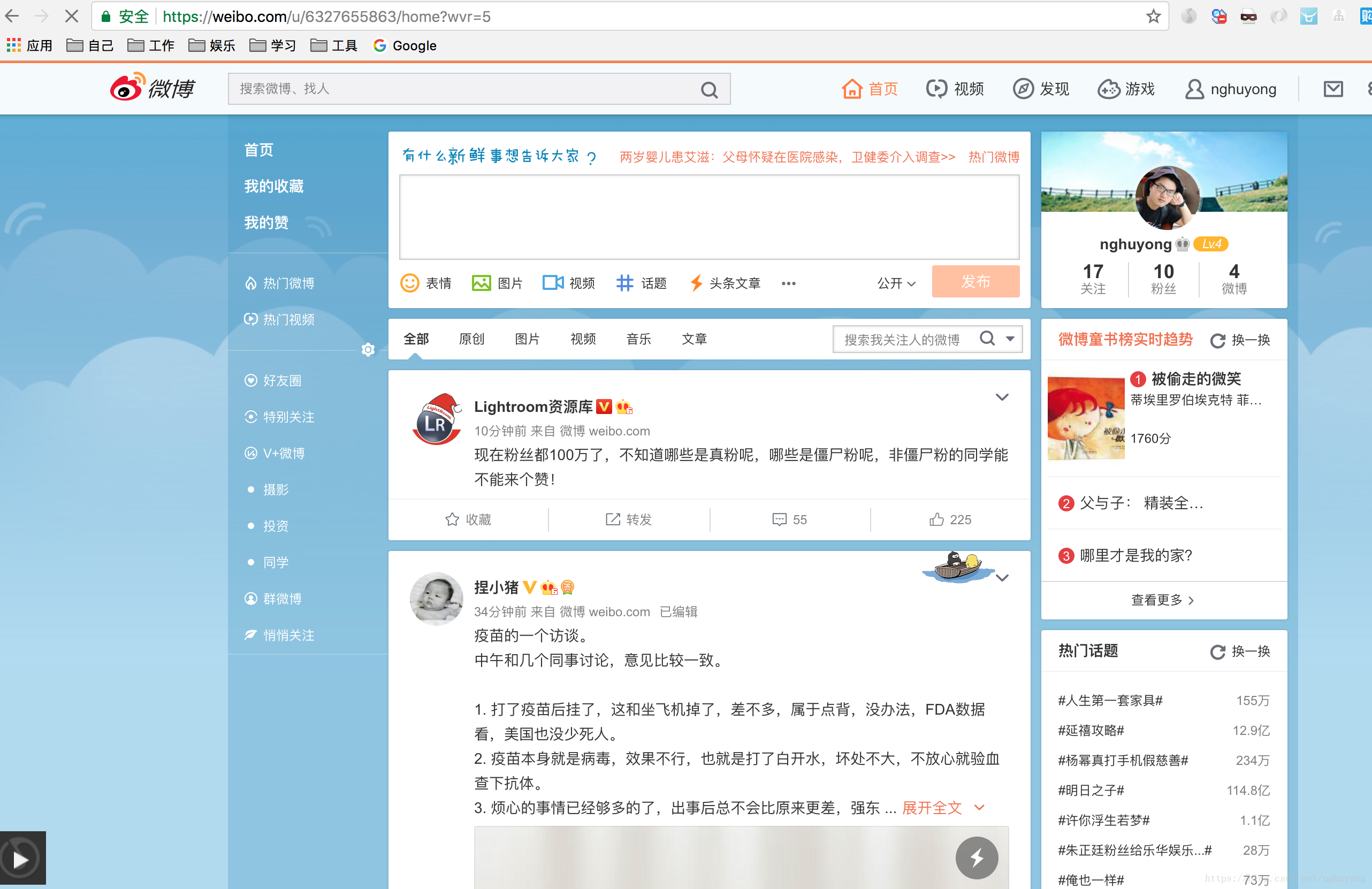
可以看到这三个站点的复杂程度是逐渐提高的,很显然,我们的微博爬虫基于最简单的weibo.cn实现。
3.3 微博登陆
要抓取到微博的数据,首先就是要登陆微博,否则就会重定向到登陆界面。而微博检测你是不是登陆了微博,就是检查你这次Request请求携带的cookie。
所以要做的事情,就是登陆微博,获取cookie存下来,以后的请求带上这个cookie即可。当然,如果不能实现微博自动化登陆,也可以手工登陆,然后复制cookie下来。BUT,这对于批量的账户,效率就会非常低。
下面,来分析以下,如果实现微博的自动化登陆。
对于自动化登陆,就是通过代码来驱动浏览器,进行微博的登陆操作,具体通过自动化工具 selenium 来实现,它支持Chrome,Firefox和PhantomJS等多种浏览器。好处就是,不用再去分析登陆时候恶心的js加密,解密的过程,直接而且简单,坏处就是效率比较慢,但是我们只是用它来完成登陆并获取cookie的操作,所以效率并不是很重要的事情。
3.3.1 weibo.cn自动化登陆
通过selenium编写浏览器的脚本,自动打开微博的手机站,点击登录,在输入框中填充账号,密码,再点击登录。最后返回cookie即可。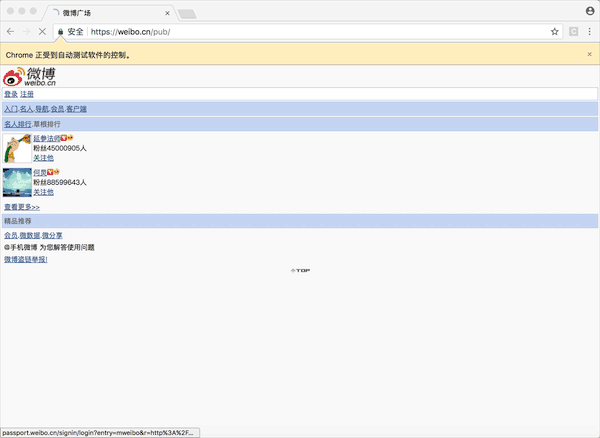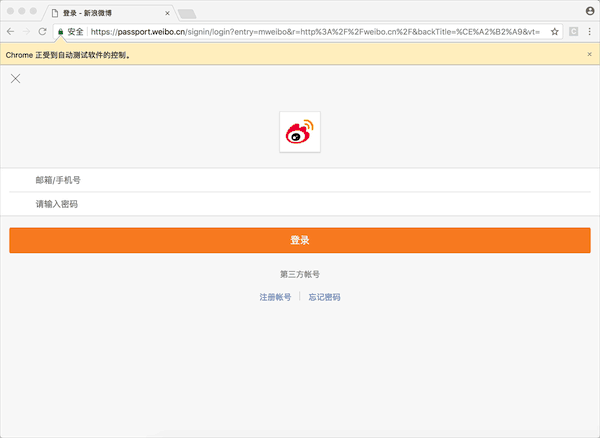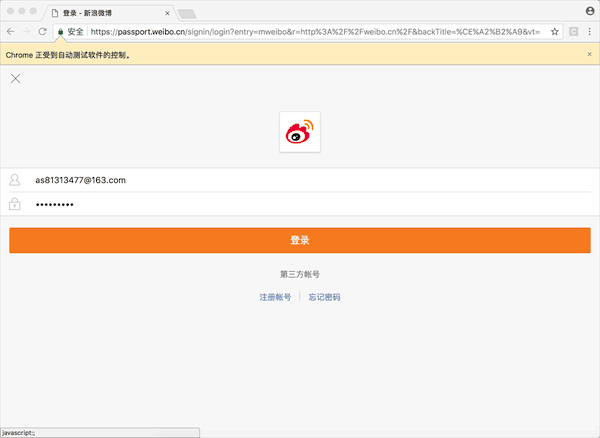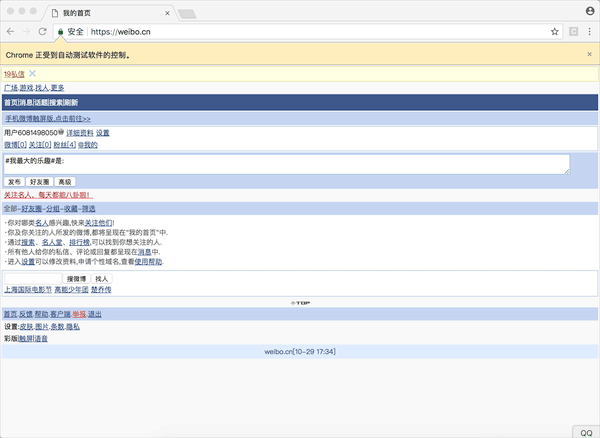
1 | |
获取cookie以后,可以保存到数据库中。以后每次request请求,随机从数据库中选一个cookie加上,就免登录了。
但是,对于网上买的小号,登陆可能会出现验证码,如下图所示:
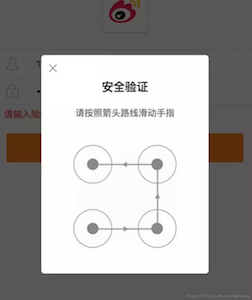
破解方案参考这里,滑动宫格验证码都给碰上了?没事儿,看完此文分分钟拿下!
UPDATE-2021-03-20: 目前weibo.cn这种方式的登陆方式已经更新了,需要手机验证码或者私信验证码,本人也有了新的破解方案,这里就不公开了,如有需要欢迎体验我们的socialsensor.top一站式科研数据服务.
3.3.2 小号购买
小号购买的讨论参见这里:微博免验证码小号购买途径[实时更新]
3.5 构建千万级的微博抓取系统
3.5.1 百万预热
要想自己构建千万级别的爬虫系统,只需要做两件事情构建账号池 和 构建IP池。
构建账号池为以下两个步骤:
- 购买大量账号
- 自动化登陆后,保存cookie到数据库中
以后每次请求,只要随机从账号池中随机选择一个账号即可。
构建IP池也为以下两个步骤:
- 选择IP代理的服务商,具体的讨论可以参见这里:请问代理ip这里怎么弄
- 进行IP验证,将可用的IP(速度满足要求)存入数据库
以后每次请求,只要随机从IP池中随机选择一个代理IP即可。
注意这里实际的抓取速度和你的账号池大小,代理IP的质量 和 电脑本身的带宽有很大关系,如果账号池不大,请求的间隔延迟就需要时间长一点,如果带宽小的话,每次请求的耗时也会长一点.
我的数据是,
账号池里230个账号,每次请求延迟为0.1秒,可以达到一天200~300万的抓取结果。
3.5.2 冲刺千万级
继续使用Redis-Scrapy框架构建一个分布式的爬虫系统,所有的爬虫共享一个Redis队列,通过Redis统一给爬虫分配URL。
可以分别部署在不同的机器上(如果一个机器带宽/CPU占用满了),或者就在一个机器上开多个进程即可。
就这样启动开了5个进程,即可达到千万的规模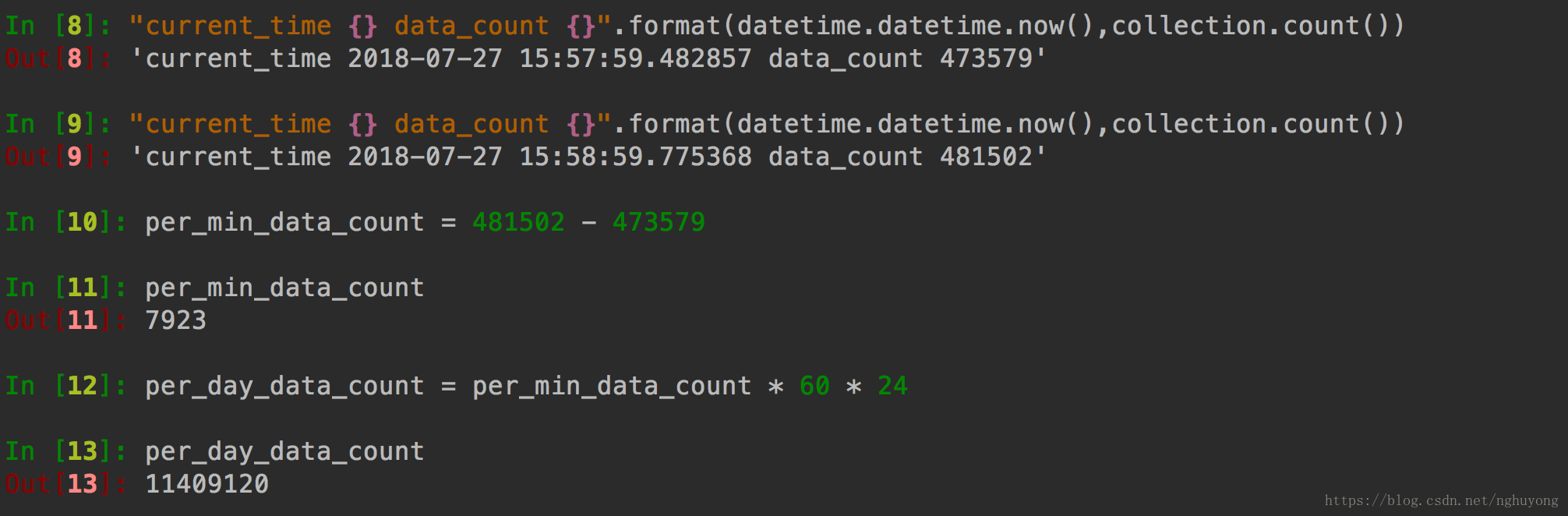
可以看到,一分钟可以抓取8000条数据,一天可达到1100万+
目前这个抓取系统目前一直在稳定运行,就此实现了最初的目标,千万级别的微博爬虫系统
结语
前文已经彻底分析介绍了微博爬虫的起源,价值和如何一步步的构建千万级的微博语料爬虫。
最后可以聊一聊对于爬虫这个事情和现在爬虫工程师这个岗位的认知。首先,爬虫本身并不违法,而且现在互联网上超过一般的流量都是爬虫。当前正处于大数据时代,那么大数据哪里来,大公司有千万上亿的用户,自然可以大数据,那么小创业公司呢,也只能通过爬虫来获取了。所以爬虫工程师,这个岗位起始在大公司和小公司都非常需要,随手拉勾搜一张图。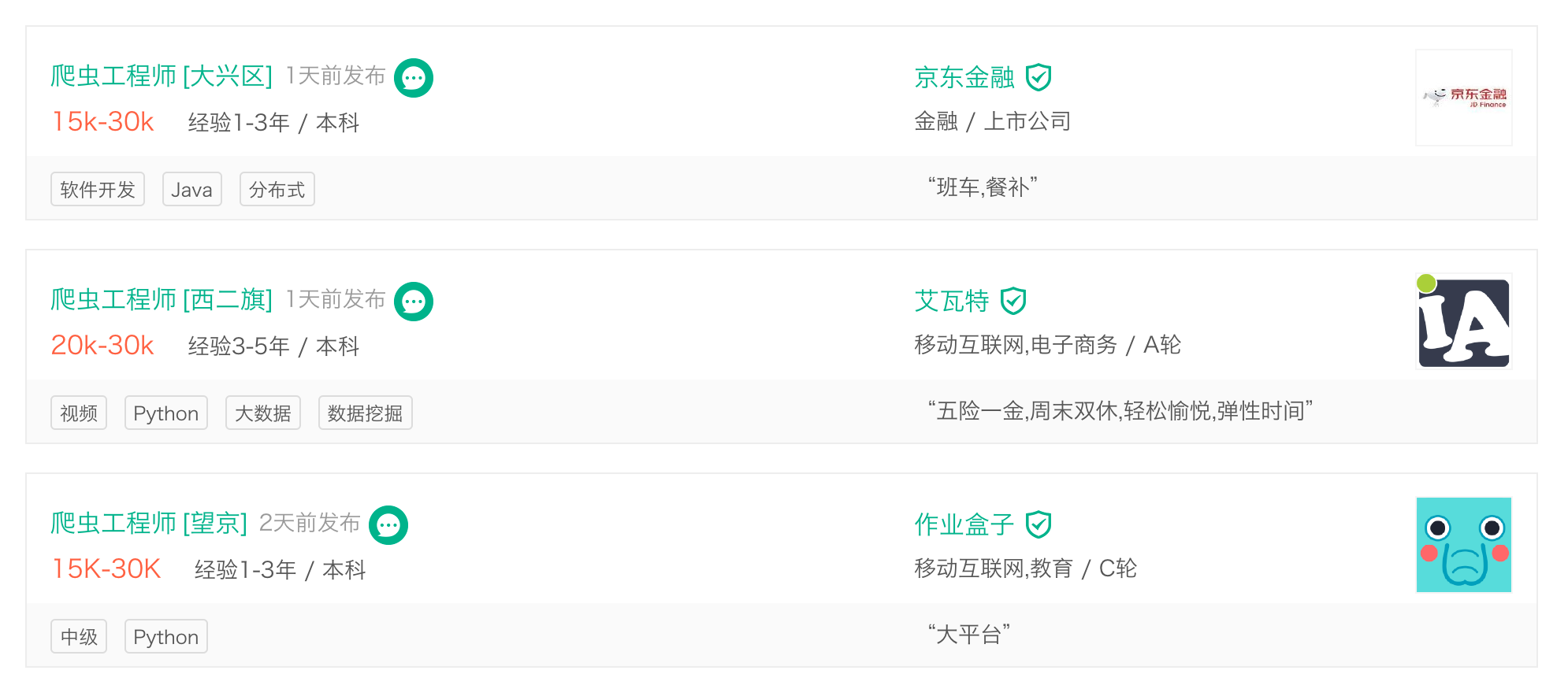
可以看到京东这样的一线公司和后面的创业公司都在招聘爬虫工程师,这是站在大数据源头的人,数据抓取的质量和效率能直接影响后面的数据产品!所以我想爬虫工程师,也需要更多的考虑如何做一个数据产品,而不单单是蒙头爬数据,可以试着学习数据分析,挖掘的知识,真正实现手中的数据就是金钱。
本次的Gitchat就到这里结束啦,有什么问题欢迎大家跟我交流.
邮箱:nghuyong@163.com
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!